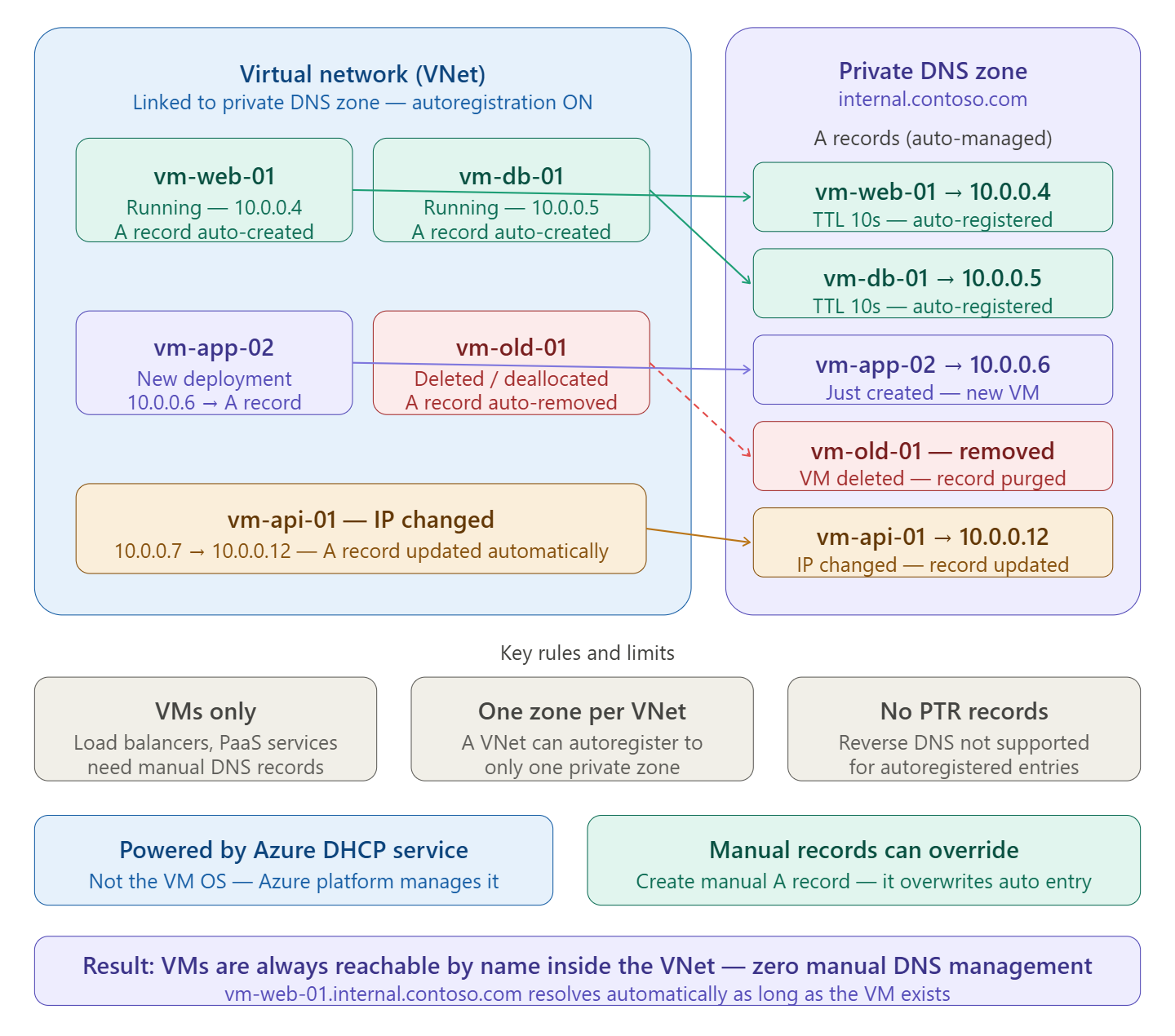
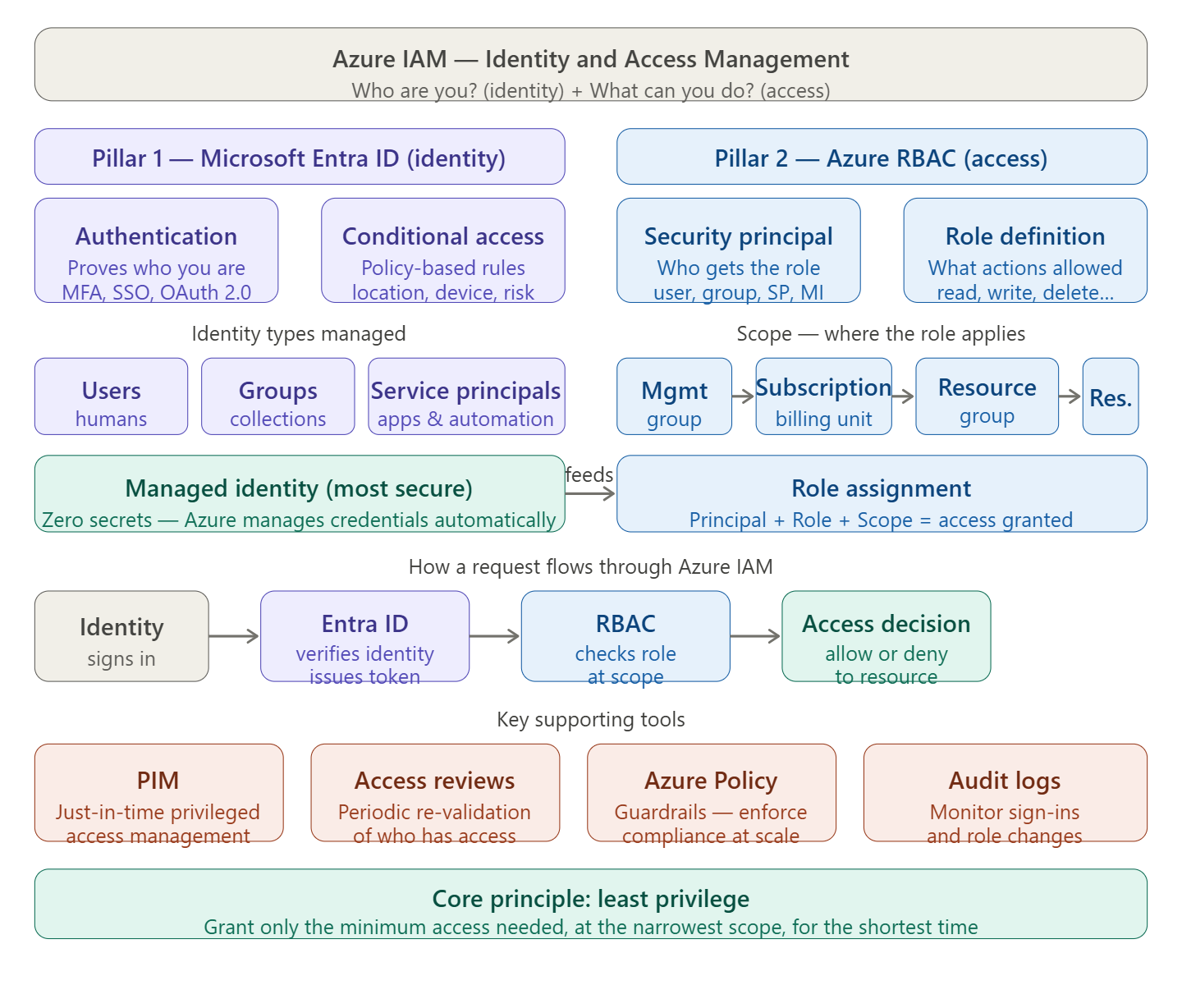
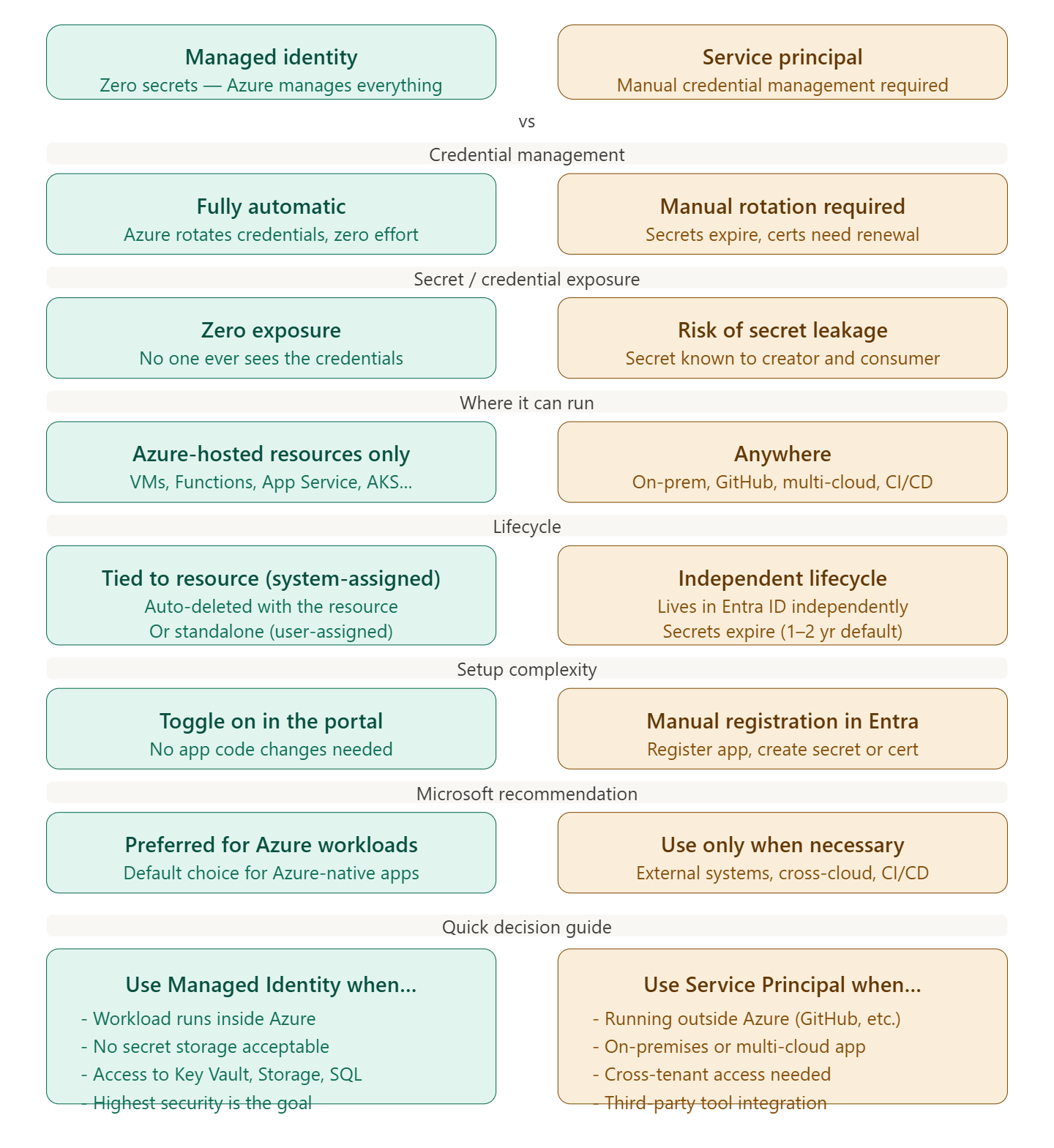
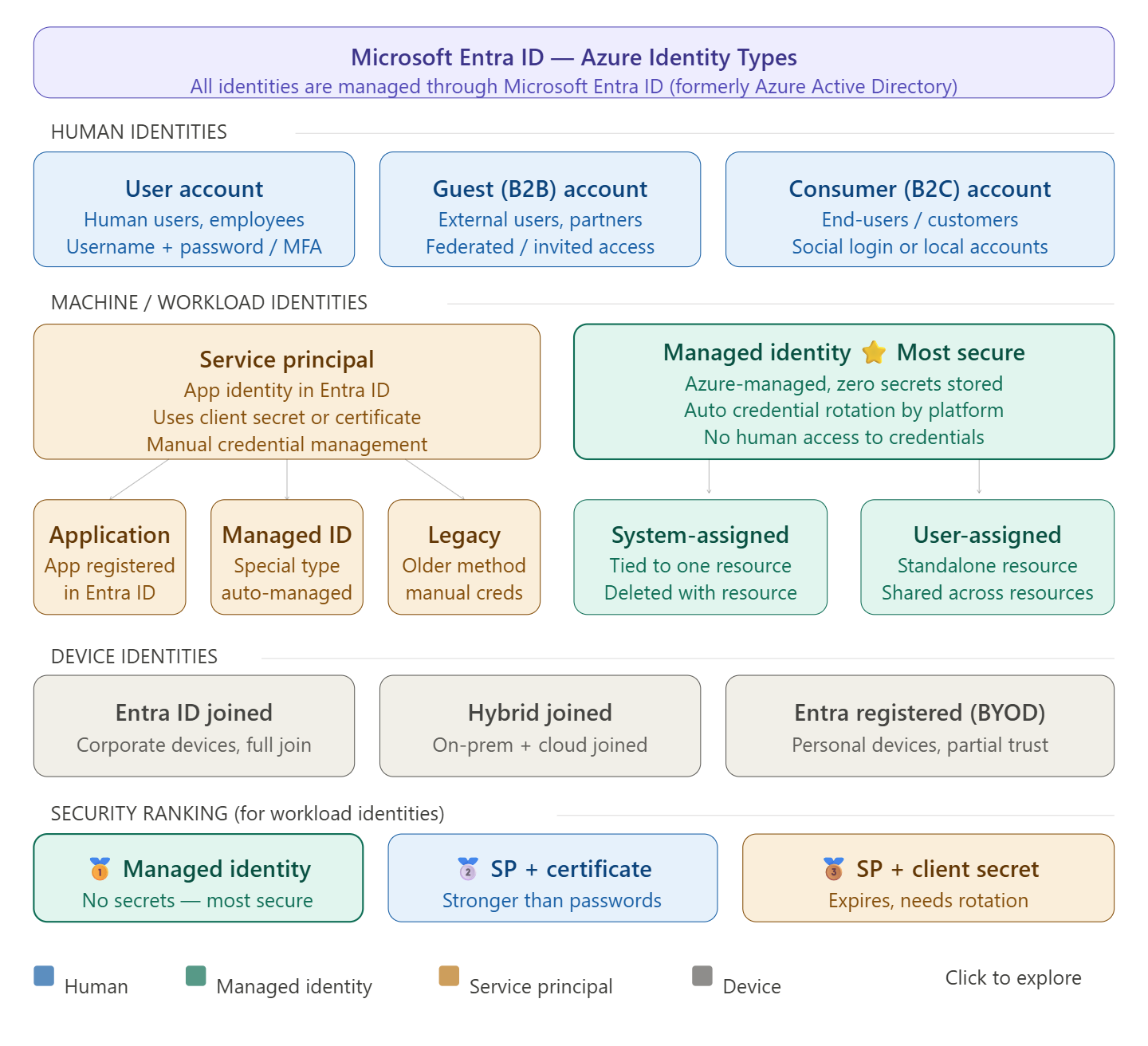
An Azure Landing Zone is the “plumbing and wiring” of your cloud environment. It is a set of best practices, configurations, and governance rules that ensure a subscription is ready to host workloads securely and at scale.
If you think of a workload (like a website or database) as a house, the Landing Zone is the city block—it provides the electricity, water, roads, and security so the house can function.
🏛️ The Conceptual Architecture
A landing zone follows a Hub-and-Spoke design, ensuring that common services (like firewalls and identity) aren’t repeated for every single application.
1. The Management Group Hierarchy
Instead of managing one giant subscription, you organize them into “folders” called Management Groups:
- Platform: Contains the “Engine Room” (Identity, Management, and Connectivity).
- Workloads (Landing Zones): Where your actual applications live (Production, Development, Sandbox).
- Decommissioned: Where old subscriptions go to die while retaining data for audit.
🏗️ The 8 Critical Design Areas
When you build a landing zone, you must make decisions in these eight categories:
- Enterprise Agreement (EA) & Tenants: How you bill and manage the top-level account.
- Identity & Access Management (IAM): Setting up Microsoft Entra ID and RBAC.
- Network Topology: Designing the Hub-and-Spoke, VNet peering, and hybrid connectivity (VPN/ExpressRoute).
- Resource Organization: Establishing a naming convention and tagging strategy.
- Security: Implementing Defender for Cloud and Azure Policy.
- Management: Centralizing logging in a Log Analytics Workspace.
- Governance: Using Azure Policy to prevent “shadow IT” (e.g., “No VMs allowed outside of East US”).
- Deployment: Using Infrastructure as Code (Terraform, Bicep, or Pulumi) to deploy the environment.
🚀 Two Main Implementation Paths
A. “Platform” Landing Zone (The Hub)
This is the central infrastructure managed by your IT/Cloud Platform team.
- Connectivity Hub: Contains Azure Firewall, VPN Gateway, and Private DNS Zones.
- Identity: Dedicated subscription for Domain Controllers or Entra Domain Services.
- Management: Centralized Log Analytics and Automation accounts.
B. “Application” Landing Zone (The Spoke)
This is a subscription handed over to a development team.
- It comes pre-configured with network peering back to the Hub.
- It has Policies already applied (e.g., “Encryption must be enabled on all disks”).
- The dev team has “Contributor” rights to build their app, but they cannot break the underlying network or security rules.
🛠️ How do you actually deploy it?
Microsoft provides the “Accelerator”—a set of templates that allow you to deploy a fully functional enterprise-scale environment in a few clicks or via code.
- Portal-based: Use the “Azure Landing Zone Accelerator” in the portal.
- Bicep/Terraform: Use the official Azure/Terraform-azurerm-caf-enterprise-scale modules.
✅ Why do it?
- Scalability: You can add 100 subscriptions without manual setup.
- Security: Guardrails are “baked in” from day one.
- Cost Control: Centralized monitoring stops “orphan” resources from running up the bill.