An Azure Landing Zone is the “plumbing and wiring” of your cloud environment. It is a set of best practices, configurations, and governance rules that ensure a subscription is ready to host workloads securely and at scale.
If you think of a workload (like a website or database) as a house, the Landing Zone is the city block—it provides the electricity, water, roads, and security so the house can function.
🏛️ The Conceptual Architecture
A landing zone follows a Hub-and-Spoke design, ensuring that common services (like firewalls and identity) aren’t repeated for every single application.
1. The Management Group Hierarchy
Instead of managing one giant subscription, you organize them into “folders” called Management Groups:
Platform: Contains the “Engine Room” (Identity, Management, and Connectivity).
Workloads (Landing Zones): Where your actual applications live (Production, Development, Sandbox).
Decommissioned: Where old subscriptions go to die while retaining data for audit.
🏗️ The 8 Critical Design Areas
When you build a landing zone, you must make decisions in these eight categories:
Enterprise Agreement (EA) & Tenants: How you bill and manage the top-level account.
Identity & Access Management (IAM): Setting up Microsoft Entra ID and RBAC.
Network Topology: Designing the Hub-and-Spoke, VNet peering, and hybrid connectivity (VPN/ExpressRoute).
Resource Organization: Establishing a naming convention and tagging strategy.
Security: Implementing Defender for Cloud and Azure Policy.
Management: Centralizing logging in a Log Analytics Workspace.
Governance: Using Azure Policy to prevent “shadow IT” (e.g., “No VMs allowed outside of East US”).
Deployment: Using Infrastructure as Code (Terraform, Bicep, or Pulumi) to deploy the environment.
🚀 Two Main Implementation Paths
A. “Platform” Landing Zone (The Hub)
This is the central infrastructure managed by your IT/Cloud Platform team.
Connectivity Hub: Contains Azure Firewall, VPN Gateway, and Private DNS Zones.
Identity: Dedicated subscription for Domain Controllers or Entra Domain Services.
Management: Centralized Log Analytics and Automation accounts.
B. “Application” Landing Zone (The Spoke)
This is a subscription handed over to a development team.
It comes pre-configured with network peering back to the Hub.
It has Policies already applied (e.g., “Encryption must be enabled on all disks”).
The dev team has “Contributor” rights to build their app, but they cannot break the underlying network or security rules.
🛠️ How do you actually deploy it?
Microsoft provides the “Accelerator”—a set of templates that allow you to deploy a fully functional enterprise-scale environment in a few clicks or via code.
Portal-based: Use the “Azure Landing Zone Accelerator” in the portal.
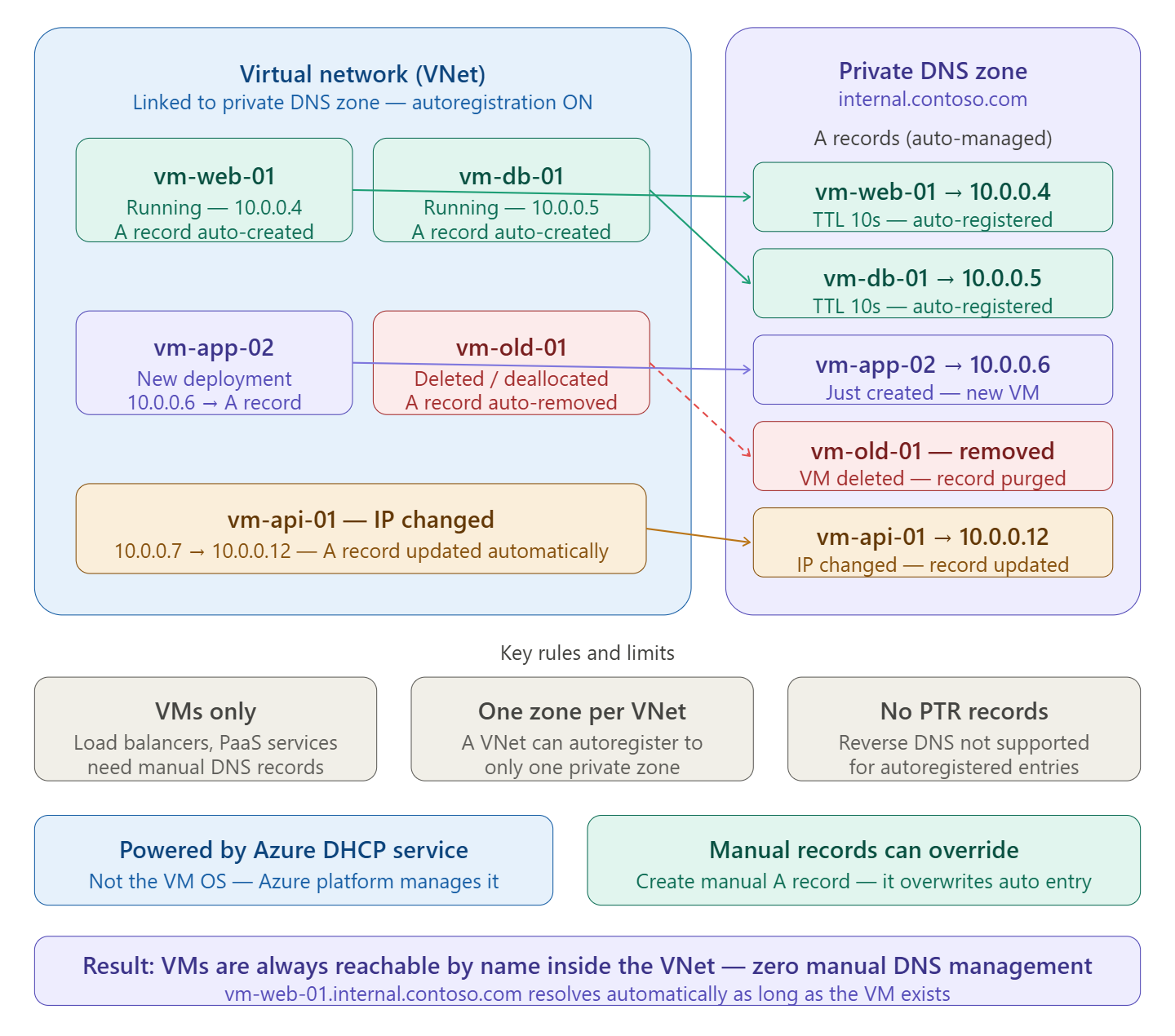
When you link a Virtual Network to a Private DNS Zone with autoregistration enabled, Azure automatically maintains DNS records for every VM in that VNet. You don’t touch the DNS zone manually — Azure handles it for you.
What happens at each VM lifecycle event
When you link a virtual network with a private DNS zone with this setting enabled, a DNS record gets created for each virtual machine deployed in the virtual network. For each virtual machine, an address (A) record is created.
If autoregistration is enabled, Azure Private DNS updates DNS records whenever a virtual machine inside the linked virtual network is created, changes its IP address, or is deleted.
So the three automatic actions are:
VM created → A record added (vm-web-01 → 10.0.0.4)
VM IP changes → A record updated automatically
VM deleted or deallocated → A record removed from the zone
What powers it under the hood
The private zone’s records are populated by the Azure DHCP service — client registration messages are ignored. This means it’s the Azure platform doing the work, not the VM’s operating system. If you configure a static IP on the VM without using Azure’s DHCP, changes to the hostname or IP won’t be reflected in the zone.
Important limits to know
A specific virtual network can be linked to only one private DNS zone when automatic registration is enabled. You can, however, link multiple virtual networks to a single DNS zone.
Autoregistration works only for virtual machines. For all other resources like internal load balancers, you can create DNS records manually in the private DNS zone linked to the virtual network.
Also, autoregistration doesn’t support reverse DNS pointer (PTR) records.
The practical benefit
In a classic setup without autoregistration, every time a VM is deployed or its IP changes, someone has to go manually update the DNS zone. With autoregistration on, your VMs are always reachable by a friendly name like vm-web-01.internal.contoso.com from anywhere inside the linked VNet — with zero manual effort, and no stale records left behind after deletions.
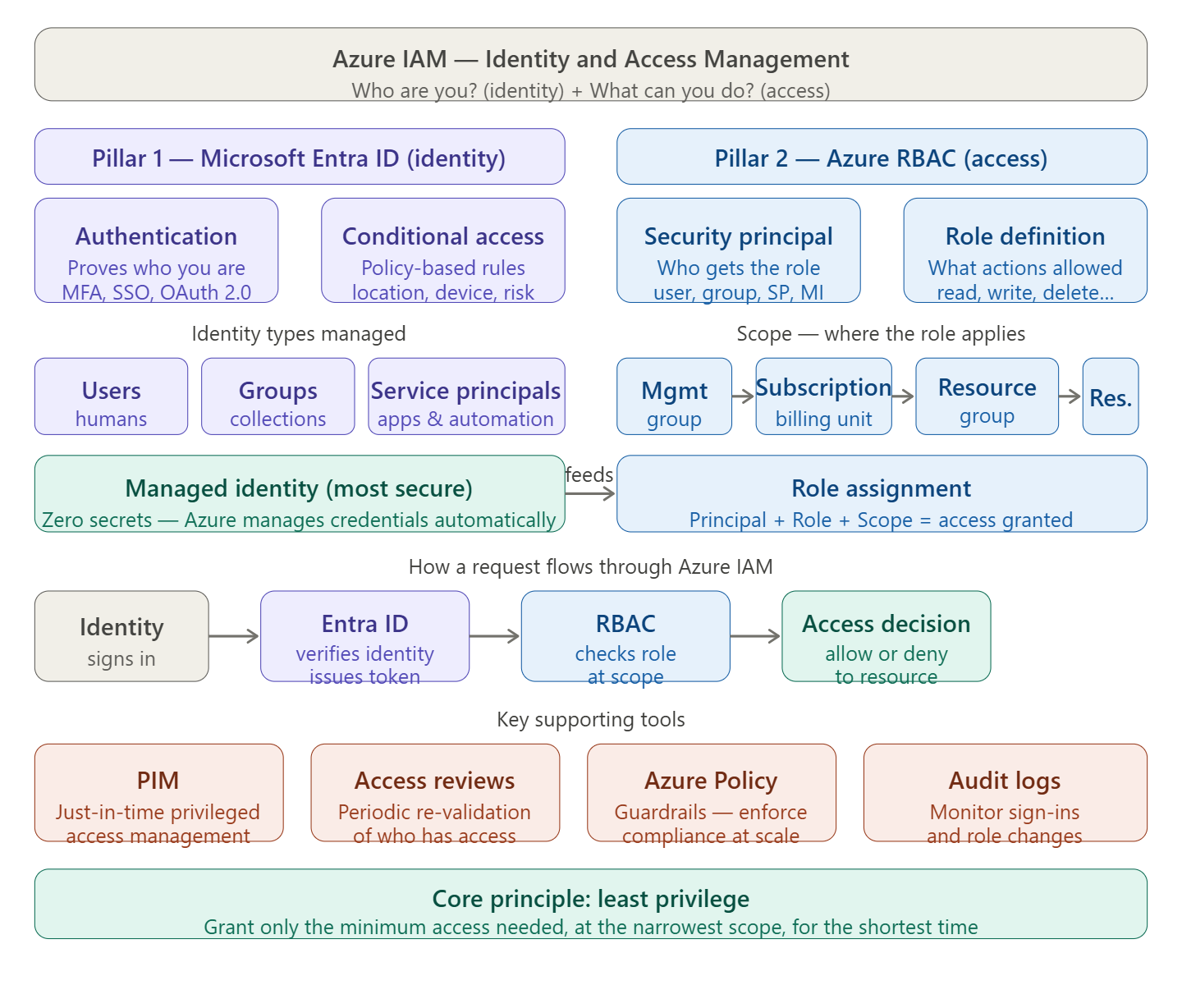
Azure IAM is best understood as two interlocking systems working together. Let me show you the big picture first, then how a request actually flows through it.Azure IAM is built around one question answered in two steps: who are you? and what are you allowed to do? Those two steps map to two distinct systems that work together.
Pillar 1 — Microsoft Entra ID (formerly Azure Active Directory): identity
This is the authentication layer. It answers “who are you?” by verifying credentials and issuing a token. It manages every type of identity in Azure: human users, guest accounts, groups, service principals (for apps and automation), and managed identities (the zero-secret identity type where Azure owns the credential). It also enforces Conditional Access policies — rules that say things like “only allow login from compliant devices” or “require MFA when signing in from outside the corporate network.”
This is the authorization layer. It answers “what can you do?” once identity is proven. RBAC works through three concepts combined into a role assignment:
A security principal — the identity receiving the role (user, group, service principal, or managed identity)
A role definition — what actions are permitted (e.g., Owner, Contributor, Reader, or a custom role)
A scope — where the role applies, which follows a hierarchy: Management Group → Subscription → Resource Group → individual Resource
A role assigned at a higher scope automatically inherits down. Give someone Reader on a subscription and they can read everything inside it.
The supporting tools
Three tools round out a mature IAM setup. PIM (Privileged Identity Management) implements just-in-time access — instead of being a permanent Owner, you request elevation for 2 hours, do the work, and the permission expires automatically. Access Reviews let you periodically re-validate who still needs access, cleaning up stale assignments. Azure Policy enforces guardrails at scale — for example, preventing anyone from assigning Owner at the subscription level without an approval workflow.
The core principle threading through all of it
Least privilege: grant the minimum role, at the narrowest scope, for the shortest duration. This is what PIM, custom roles, and resource-group-level assignments all support — shrinking the blast radius if any identity is ever compromised.
What makes managed identities uniquely secure is that no one knows the credentials — they are automatically created by Azure, including the credentials themselves. This eliminates the biggest risk in cloud security: leaked or hardcoded secrets. Managed identity replaces secrets such as access keys or passwords, and can also replace certificates or other forms of authentication for service-to-service dependencies.
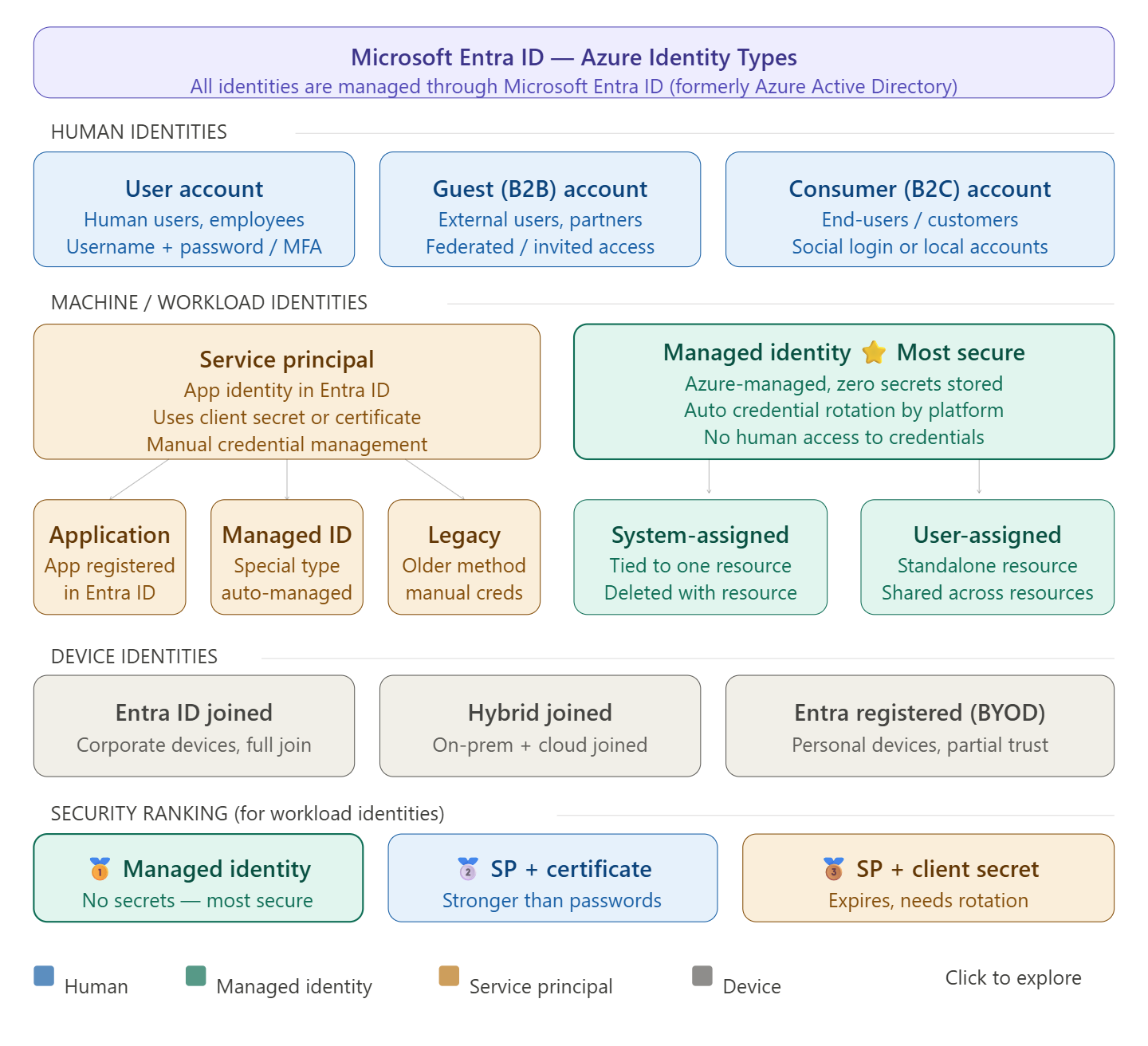
How many identity types are there in Azure?
At a high level, there are two types of identities: human and machine/non-human identities. Machine/non-human identities consist of device and workload identities. In Microsoft Entra, workload identities are applications, service principals, and managed identities.
Breaking it down further, Azure has 4 main categories with several sub-types:
1. Human identities
User accounts (employees, admins)
Guest/B2B accounts (external partners)
Consumer/B2C accounts (end-users via social login)
2. Workload/machine identities
Managed Identity — most secure; no secrets to manage
System-assigned: tied to the lifecycle of an Azure resource; when the resource is deleted, Azure automatically deletes the service principal.
User-assigned: a standalone Azure resource that can be assigned to one or more Azure resources — the recommended type for Microsoft services.
Service Principal — three main types exist: Application service principal, Managed identity service principal, and Legacy service principal.
3. Device identities
Entra ID joined (corporate devices)
Hybrid joined (on-prem + cloud)
Entra registered / BYOD (personal devices)
Why prefer Managed Identity over Service Principal?
Microsoft Entra tokens expire every hour, reducing exposure risk compared to Personal Access Tokens which can last up to one year. Managed identities handle credential rotation automatically, and there is no need to store long-lived credentials in code or configuration. Service principals, by contrast, require you to manually rotate client secrets or certificates — a 2025 report highlighted that 23.77 million secrets were leaked on GitHub in 2024 alone, underscoring the risks of hardcoded credentials.
The rule of thumb: use Managed Identity whenever your workload runs inside Azure. Use a Service Principal only when you need to authenticate from outside Azure (CI/CD pipelines, on-premises systems, multi-cloud).
The CIDR (Classless Inter-Domain Routing) notation tells you two things: the starting IP address and the size of your network.
The number after the slash (e.g., /16, /24) represents how many bits are “locked” for the network prefix. Since an IPv4 address has 32 bits in total, you subtract the CIDR number from 32 to find how many bits are left for your “hosts” (the actual devices).
📏 The “Rule of 32”
To calculate how many IPs you get, use this formula: $2^{(32 – \text{prefix})}$.
Higher number = Smaller network:/28 is a small room.
Lower number = Larger network:/16 is a massive warehouse.
Common Azure CIDR Sizes
CIDR
Total IPs
Azure Usable IPs*
Common Use Case
/16
65,536
65,531
VNet Level: A massive space for a whole company’s environment.
/22
1,024
1,019
VNet Level: Good for a standard “Hub” network.
/24
256
251
Subnet Level: Perfect for a standard Web or App tier.
/27
32
27
Service Subnet: Required for things like SQL Managed Instance.
/28
16
11
Micro-Subnet: Used for small things like Azure Bastion or Gateways.
/29
8
3
Minimum Size: The smallest subnet Azure allows.
🚫 The “Azure 5” (Critical)
In every subnet you create, Azure automatically reserves 5 IP addresses. You cannot use these for your VMs or Apps.
If you create a /28 (16 IPs), you only get 11 usable addresses.
x.x.x.0: Network Address
x.x.x.1: Default Gateway
x.x.x.2 & x.x.x.3: Azure DNS mapping
x.x.x.255: Broadcast Address
💡 How to choose for your VNet?
When designing your Azure network, follow these two golden rules:
Don’t go too small: It is very difficult to “resize” a VNet once it’s full of resources. It’s better to start with a /16 or /20 even if you only need a few IPs today.
Plan for Peering: If you plan to connect VNet A to VNet B (Peering), their CIDR ranges must not overlap. If VNet A is 10.0.0.0/16, VNet B should be something completely different, like 10.1.0.0/16.
While both Service Endpoints and Private Endpoints are designed to secure your traffic by keeping it on the Microsoft backbone network, they do so in very different ways.
The simplest way to remember the difference is: Service Endpoints secure a public entrance, while Private Endpoints build a private side door.
🛠️ Service Endpoints
Service Endpoints “wrap” your virtual network identity around an Azure service’s public IP.
The Connection: Your VM still talks to the Public IP of the service (e.g., 52.x.x.x), but Azure magically reroutes that traffic so it never leaves the Microsoft network.
Granularity: It is broad. If you enable a Service Endpoint for “Storage,” your subnet can now reach any storage account in that region via the backbone.
On-Premise: Does not work for on-premise users. A user in your office cannot use a Service Endpoint to reach a database over a VPN.
Cost: Completely Free.
🔒 Private Endpoints (Powered by Private Link)
Private Endpoints actually “inject” a specific service instance into your VNet by giving it a Private IP address from your own subnet.
The Connection: Your VM talks to a Private IP (e.g., 10.0.0.5). To the VM, the database looks like just another server in the same room.
Granularity: Extremely high. The IP address is tied to one specific resource (e.g., only your “Production-DB”). You cannot use that same IP to reach a different database.
On-Premise:Fully supports on-premise connectivity via VPN or ExpressRoute. Your office can reach the database using its internal 10.x.x.x IP.
Cost: There is a hourly charge plus a fee for data processed (roughly $7-$8/month base + data).
📊 Comparison Table
Feature
Service Endpoint
Private Endpoint
Destination IP
Public IP of the Service
Private IP from your VNet
DNS Complexity
None (Uses public DNS)
High (Requires Private DNS Zones)
Granularity
Subnet to All Services in Region
Subnet to Specific Resource
On-Prem Access
No
Yes (via VPN/ExpressRoute)
Data Exfiltration
Possible (if not restricted)
Protected (bound to one instance)
Cost
Free
Paid (Hourly + Data)
🚀 Which one should you use?
Use Service Endpoints if:
You have a simple setup and want to save money.
You only need to connect Azure-to-Azure (no on-premise users).
You don’t want to deal with the headache of managing Private DNS Zones.
Use Private Endpoints if:
Security is your #1 priority (Zero Trust).
You need to reach the service from your on-premise data center.
You must strictly prevent “Data Exfiltration” (ensuring employees can’t copy data from your VNet to their own personal storage accounts).
You are in a highly regulated industry (Finance, Healthcare, Government).
Expert Tip: In 2026, most enterprises have moved toward Private Endpoints as the standard. While they are more expensive and harder to set up (DNS is the biggest hurdle), they offer the “cleanest” security architecture for a hybrid cloud environment.
This is a classic “architectural corner” that many engineers find themselves in. When an Azure Virtual Network (VNet) or its subnets are out of IP addresses, you cannot simply “resize” a subnet that has active resources in it.
Here is the hierarchy of solutions, from the easiest to the most complex.
🛠️ Option 1: The “Non-Disruptive” Fix (Add Address Space)
In 2026, Azure allows you to expand a VNet without taking it down. You can add a Secondary Address Space to the VNet.
Add a New Range: Go to the VNet > Address space and add a completely new CIDR block (e.g., if you used 10.0.0.0/24, add 10.1.0.0/24).
Create a New Subnet: Create a new subnet (e.g., Subnet-2) within that new range.
Deploy New Workloads: Direct all new applications or VMs to the new subnet.
Sync Peerings: If this VNet is peered with others, you must click the Sync button on the peering configuration so the other VNets “see” the new IP range.
🔄 Option 2: The “Migration” Fix (VNet Integration)
If your existing applications need more room to grow (scaling up) but their current subnet is full:
Create a Parallel Subnet: Add a new, larger subnet to the VNet (assuming you have space in the address range).
Migrate Resources: For VMs, you can actually change the subnet of a Network Interface (NIC) while the VM is stopped.
App Services: If you are using VNet Integration for App Services, simply disconnect the integration and reconnect it to a new, larger subnet.
🌐 Option 3: The “Expansion” Fix (VNet Peering)
If you cannot add more address space to your current VNet (perhaps because it would overlap with your on-prem network), you can “spill over” into a second VNet.
Create VNet-B: Set up a brand new VNet with its own IP range.
Peer them: Use VNet Peering to connect VNet-A and VNet-B.
Routing: Use Internal Load Balancers or Private Endpoints to bridge the gap between applications in both networks.
⚠️ Important “Gotchas” to Remember
The “Azure 5”: Remember that Azure reserves 5 IP addresses in every subnet (the first four and the last one). If you create a /29 subnet, you think you have 8 IPs, but you actually only have 3 usable ones.
Subnet Resizing: You cannot resize a subnet if it has any resources in it (even one dormant NIC). You must delete the resources or move them first.
NAT Gateway: In 2026, if you are running out of Public IPs for outbound traffic, attach an Azure NAT Gateway to your subnet. This allows up to 64,000 concurrent flows using a single public IP, preventing “SNAT Port Exhaustion.”
💡 The “Pro” Recommendation:
If this is a production environment, use Option 1. Add a secondary address space (like 172.16.0.0/16 or 100.64.0.0/10 if you’re out of 10.x.x.x space) and start a new subnet. It’s the only way to get more IPs without a “stop-everything” maintenance window.
When discussing “peering” in Azure, it’s important to clarify the context. Usually, this refers to VNet Peering (connecting virtual networks) or Direct Peering (which can refer to Azure Peering Service for optimized internet or ExpressRoute Direct for high-speed private fiber).
Here is what you need to consider for each to ensure a secure and performant design.
1. VNet Peering (Connecting VNets)
VNet Peering is the primary way to connect two Azure Virtual Networks. They behave as a single network using private IP addresses.
🔑 Key Considerations:
Address Space Overlap:CRITICAL. You cannot peer VNets if their IP address spaces (CIDR blocks) overlap. Plan your IP schema early; fixing an overlap later requires deleting and recreating the VNet.
Transitivity: VNet peering is not transitive. If VNet A is peered with VNet B, and VNet B is peered with VNet C, VNet A cannot talk to VNet C.
Solution: Use a Hub-and-Spoke model with an Azure Firewall/NVA or Azure Virtual WAN for transitive routing.
Gateway Transit: If VNet A has a VPN/ExpressRoute gateway, you can allow VNet B to use it.
Check: Enable “Allow gateway transit” on VNet A and “Use remote gateways” on VNet B.
Cost: Local peering (same region) is cheaper than Global peering (different regions). You are charged for both inbound and outbound data transfer on both sides of the peering.
2. Direct Peering (ExpressRoute Direct & Peering Service)
“Direct Peering” usually refers to ExpressRoute Direct, where you connect your own hardware directly to Microsoft’s edge routers at 10 Gbps or 100 Gbps.
🔑 Key Considerations:
Physical Connectivity: You are responsible for the “Last Mile” fiber from your data center to the Microsoft Peering Location.
SKU Selection: * Local: For traffic within the same geopolitical region (cheapest).
Standard: For traffic within the same continent.
Premium: Required for global connectivity and more than 10 VNet links.
Microsoft Peering vs. Private Peering:
Private Peering: Connects your on-prem network to your Azure VNets (internal traffic).
Microsoft Peering: Connects your on-prem network to Microsoft 365, Dynamics 365, and Azure Public PaaS services (Storage, SQL) over a private link.
3. Comparison Summary
Consideration
VNet Peering
Direct Peering (ExpressRoute Direct)
Primary Use
Cloud-to-Cloud connectivity.
On-Prem-to-Cloud (High Bandwidth).
Medium
Microsoft Global Backbone.
Dedicated Physical Fiber + Backbone.
Bandwidth
Limited by VM/Gateway SKU.
Up to 100 Gbps.
Complexity
Low (Point-and-click).
High (Requires physical fiber/BGP).
Security
Encapsulated in Azure backbone.
Private, dedicated physical path.
🚦 Common Pitfall: Asymmetric Routing
If you have both a VNet Peering and an ExpressRoute circuit connecting the same two locations, Azure might send traffic out via the peering but receive it back via ExpressRoute.
The Fix: Use User-Defined Routes (UDRs) or BGP weights to ensure the “return” path matches the “outbound” path. Azure will prioritize VNet Peering routes over ExpressRoute routes by default if the address prefixes are the same.
Would you like a specific KQL query to monitor the latency or throughput between your peered networks?
It sounds like you are describing a “Traffic Spike” or perhaps a “Burst” in resource usage. Since there are no alerts, you are in “detective mode,” looking for a silent surge that hasn’t crossed a threshold yet but is clearly visible in your telemetry.
If you heard “frost,” you might be referring to “Cold Start” spikes (common in Serverless/Functions) or a “Request Spike.” Here are the steps to track down the source of a sudden surge in Azure:
🔍 Step 1: Use Azure Monitor “Metrics Explorer”
Since you don’t have alerts, you need to visualize the spike to see its “shape.”
Go to the resource (e.g., App Service, VM, or Load Balancer).
Select Metrics from the left menu.
Add the Request Count (for apps) or CPU/Network In (for VMs) metric.
The Secret Step: Change the “Aggregation” to Count or Sum and look for the exact timestamp of the spike.
Apply Splitting: Split the metric by “RemoteIP” or “Instance”. This tells you if the spike is coming from one specific user/IP or hitting one specific server.
🕵️ Step 2: Dig into Log Analytics (KQL)
If the metrics show a spike but not the “who,” you need the logs. This is where you find the “Source.”
Go to Logs (Log Analytics Workspace).
Run a query to find the top callers during that spike period.
Example KQL for App Gateways/Web Apps:
Code snippet
// Find the top 10 IP addresses causing the spike
AzureDiagnostics
| where TimeGenerated > datetime(2026-04-10T12:00:00Z) // Set to your spike time
| where Category == "ApplicationGatewayAccessLog"
| summarize RequestCount = count() by clientIP_s
| top 10 by RequestCount
Result: If one IP address has 50,000 requests while others have 10, you’ve found a bot or a misconfigured client.
If the spike is happening inside your application code (e.g., a “Cold Start” or a heavy API call):
Go to Application Insights > Failures or Performance.
Look at the “Top 10 Operations”.
Check if a specific API endpoint (e.g., /api/export) suddenly jumped in volume.
Use User Map to see if the traffic is coming from a specific geographic region (e.g., a sudden burst of traffic from a country you don’t usually service).
🗺️ Step 4: Network Watcher (Infrastructure Level)
If you suspect the spike is at the “packet” level (like a DDoS attempt or a backup job gone rogue):
Go to Network Watcher > NSG Flow Logs.
Use Traffic Analytics. It provides a map showing which VNets or Public IPs are sending the most data.
Check for “Flows”: It will show you the “Source Port” and “Destination Port.” If you see a spike on Port 22 (SSH) or 3389 (RDP), someone is likely trying to brute-force your VMs.
🤖 Step 5: Check for “Auto-Scaling” Events
Sometimes the “spike” isn’t a problem, but a reaction.
Go to Activity Log.
Filter for “Autoscale” events.
If the spike happened exactly when a new instance was added, the “spike” might actually be the resource “warming up” (loading caches, etc.), which can look like a surge in CPU or Disk I/O.
Summary Checklist:
Metrics Explorer: To see when it happened and how big it was.
Log Analytics (KQL): To find the specific Client IP or User Agent.
Traffic Analytics: To see if it was a Network-level burst.
Activity Log: To see if any Manual Changes or Scaling occurred at that exact second.
A common real-world “mystery spike” case. Since you mentioned “frost spike” and “source space,” you are likely referring to a Cost Spike or a Request/Throughput Spike in your resource namespace.
If there are no alerts firing, it means the spike either didn’t hit a specific threshold or was too brief to trigger a standard “Static” alert.
🏗️ Step 1: Establish the “When” and “What”
First, you need to see the “DNA” of the spike using Azure Monitor Metrics.
Look at the Graph: Is it a “Square” spike (starts and stops abruptly, like a scheduled job)? Or a “Needle” spike (hits a peak and drops, like a bot attack)?
Identify the Resource: Go to Metrics Explorer and check:
For VMs:Percentage CPU or Network In/Out.
For Storage/SQL:Transactions or DTU Consumption.
For App Services:Requests or Data In.
🔍 Step 2: Finding the Source (The Detective Work)
Since you don’t know where it came from, you use “Splitting” and “Filtering” in Metrics Explorer.
Split by Instance/Role: If you have 10 servers, split by InstanceName. Does only one server show the spike? If yes, it’s a local process (like a hanging Windows Update or a log-rotation fail).
Split by Operation: For Storage or SQL, split by API Name. Is it GetBlob? PutBlob? This tells you if you are reading too much or writing too much.
Split by Remote IP: If your load balancer shows the spike, split by ClientIP. If one IP has 100x the traffic of others, you’ve found your source.
🕵️ Step 3: Deep Dive with Log Analytics (KQL)
Metrics only show numbers. Logs show names. You need to run a KQL query in your Log Analytics Workspace.
Query to find “Who is talking to me”:
Code snippet
// This finds the top 5 callers during the spike window
AzureDiagnostics
| where TimeGenerated > datetime(2026-04-10T12:00:00Z) // Use your spike time
| summarize RequestCount = count() by clientIp_s, requestUri_s
| top 5 by RequestCount
Result: This will literally list the IP address and the specific URL they were hitting.
💰 Step 4: The “Cost” Investigation
If the spike is financial (a “Cost Spike”), you check Azure Cost Management.
Cost Analysis: View cost by Resource. Did one specific Disk or Data Transfer cost jump?
Check for “Orphaned” Resources: Sometimes a spike comes from a process that created 1,000 snapshots or temporary disks and forgot to delete them.
🤖 Step 5: Check the “Silent” Sources
If the metrics and logs don’t show an external attacker, check internal Azure “automated” sources:
Resource Graph: Check for “Change Tracking.” Did someone deploy code or change a firewall rule at that exact minute?
Backup/Recovery Services: A “huge spike” in disk I/O often aligns with a Storage Snapshot or an Azure Backup job starting.
Defender for Cloud: Even if you don’t have a “Metric Alert,” check the Security Alerts. Defender might have seen the spike and flagged it as “Suspicious PowerShell Activity” or “Port Scanning.”
✅ Summary Checklist
Step
Action
Tool
1. Visualize
See the shape and duration of the spike.
Metrics Explorer
2. Isolate
Split metrics by IP or Instance.
Metrics Explorer
3. Identify
Run a query to find the specific Client IP or User.
Log Analytics (KQL)
4. Correlate
Check if any “Deployments” happened at that time.
Activity Log / Change Analysis
5. Network
Check for massive data transfers between regions.
Network Watcher / Traffic Analytics
How to prevent this next time? Once you find the source, create a Dynamic Threshold Alert. Unlike static alerts, these use AI to learn your “normal” pattern and will fire if a spike looks “unusual,” even if it doesn’t hit a high maximum number.