OpenShift Container Platform on Azure — ARO Best Practices
Azure Red Hat OpenShift (ARO) is a fully managed OpenShift 4 service jointly operated by Microsoft and Red Hat — both companies share responsibility for the control plane, infrastructure, and SLA (99.95%).
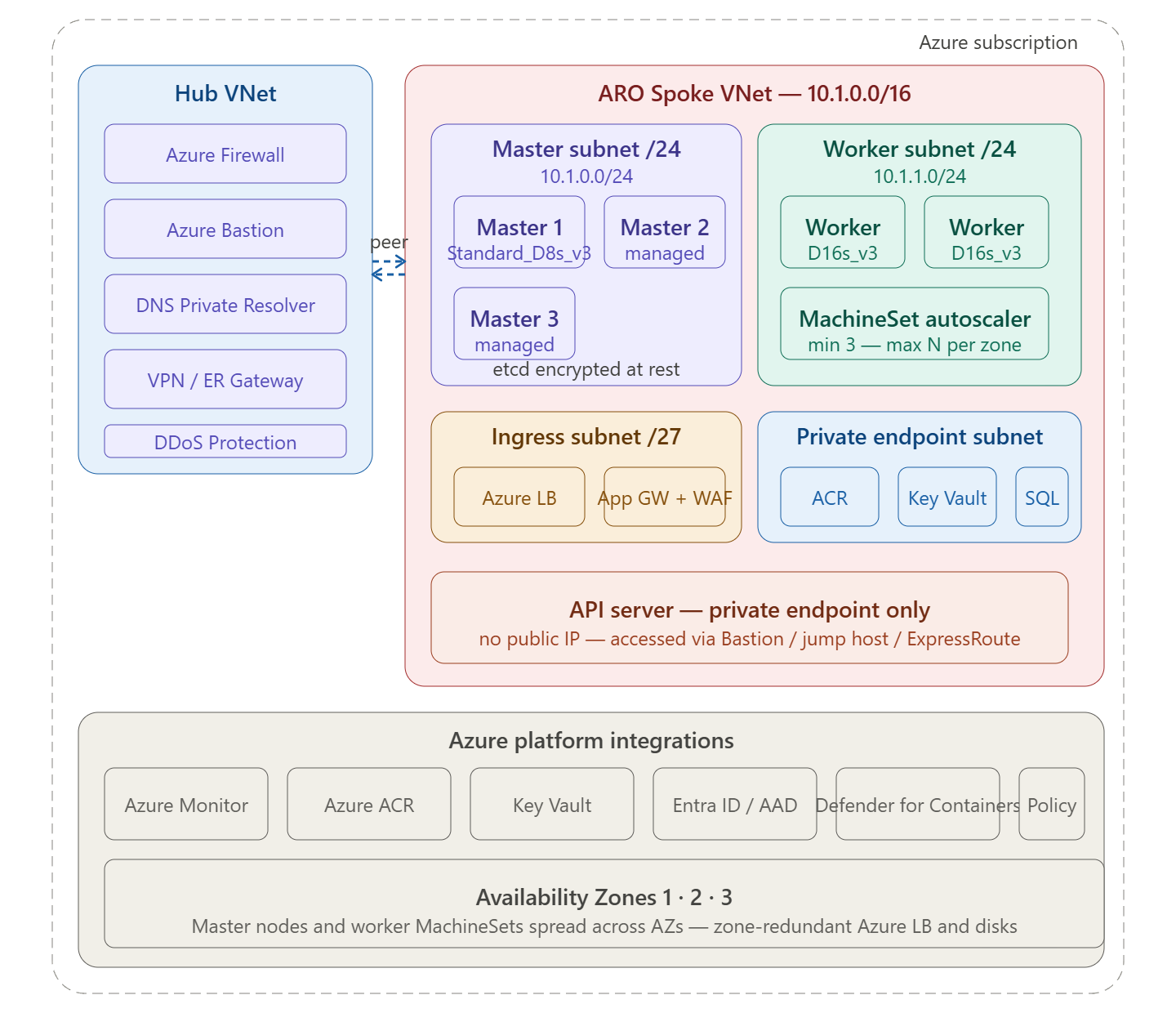
1. Networking Best Practices
Always deploy a private cluster
A private ARO cluster hides the Kubernetes API server behind a private endpoint — no public IP, unreachable from the internet:
az aro create \ --resource-group rg-aro \ --name aro-prod \ --vnet aro-spoke-vnet \ --master-subnet master-subnet \ --worker-subnet worker-subnet \ --apiserver-visibility Private \ # ← API server private --ingress-visibility Private \ # ← ingress private --pull-secret @pull-secret.txt
Access to the private API server is then through Azure Bastion → jump host, or over ExpressRoute/VPN from on-premises.
Subnet sizing — get this right before deployment (cannot resize after)
ARO consumes IP addresses aggressively — every pod gets its own IP from the node’s subnet range:
| Subnet | Minimum | Recommended | Notes |
|---|---|---|---|
| Master subnet | /27 | /24 | Fixed 3 masters — needs room for Azure infra IPs |
| Worker subnet | /27 | /23 or /22 | Every pod consumes an IP — size generously |
| Ingress subnet | /28 | /27 | For LB / App Gateway front-end IPs |
| Private endpoints | /28 | /27 | One IP per private endpoint |
Worker subnet sizing example: /23 = 512 addresses Azure reserves 5 Available: 507 Max pods per node: 250 (default OpenShift SDN) Nodes supportable: ~2 per node × workers Plan for: 3× current need for growth headroom
Egress lockdown via Azure Firewall
ARO requires outbound internet access for Red Hat update servers, telemetry, and pull.registry.redhat.io. Lock this down with Azure Firewall application rules rather than allowing all outbound:
Azure Firewall Application Rules for ARO egress: ┌─────────────────────────────────────────────────────────┐ │ Name Target FQDN │ ├─────────────────────────────────────────────────────────┤ │ aro-rh-registry registry.redhat.io │ │ registry.access.redhat.com │ │ quay.io │ │ cdn.quay.io │ ├─────────────────────────────────────────────────────────┤ │ aro-azure-services *.blob.core.windows.net │ │ *.servicebus.windows.net │ │ *.table.core.windows.net │ ├─────────────────────────────────────────────────────────┤ │ aro-monitoring *.ods.opinsights.azure.com │ │ *.oms.opinsights.azure.com │ ├─────────────────────────────────────────────────────────┤ │ aro-rh-telemetry cert-api.access.redhat.com │ │ api.access.redhat.com │ └─────────────────────────────────────────────────────────┘
Apply a UDR on the master and worker subnets pointing 0.0.0.0/0 to the Azure Firewall private IP — same hub and spoke pattern as any spoke workload.
Use a custom DNS server
Point the ARO VNet DNS to your hub DNS Private Resolver so cluster nodes can resolve private endpoints and internal domains:
az network vnet update \ --resource-group rg-aro-network \ --name aro-spoke-vnet \ --dns-servers 10.0.5.4 # DNS Private Resolver inbound endpoint IP
2. Availability and Resilience Best Practices
Spread across all three Availability Zones
ARO deploys 3 master nodes — one per AZ automatically. Workers must be explicitly spread via MachineSets:
# MachineSet for AZ1 — replicate for AZ2, AZ3apiVersion: machine.openshift.io/v1beta1kind: MachineSetmetadata: name: aro-prod-worker-eastus-1 namespace: openshift-machine-apispec: replicas: 3 template: spec: providerSpec: value: zone: "1" # AZ1 vmSize: Standard_D16s_v3 osDisk: diskSizeGB: 128 managedDisk: storageAccountType: Premium_LRS
Create three MachineSets — one per zone — with equal replica counts. This ensures workloads survive a full AZ failure.
Enable cluster autoscaler
apiVersion: autoscaling.openshift.io/v1kind: ClusterAutoscalermetadata: name: defaultspec: resourceLimits: maxNodesTotal: 24 scaleDown: enabled: true delayAfterAdd: 10m delayAfterDelete: 5m delayAfterFailure: 30s---apiVersion: autoscaling.openshift.io/v1beta1kind: MachineAutoscalermetadata: name: aro-prod-worker-eastus-1 namespace: openshift-machine-apispec: minReplicas: 3 maxReplicas: 8 scaleTargetRef: kind: MachineSet name: aro-prod-worker-eastus-1
Use zone-redundant storage for persistent volumes
apiVersion: storage.k8s.io/v1kind: StorageClassmetadata: name: managed-premium-zrsprovisioner: disk.csi.azure.comparameters: skuName: Premium_ZRS # Zone-redundant storage — survives AZ failure cachingMode: ReadOnlyreclaimPolicy: Retain # Retain on PVC delete — prevents data lossvolumeBindingMode: WaitForFirstConsumerallowVolumeExpansion: true
Use Premium_ZRS instead of Premium_LRS for stateful workloads — ZRS replicates the disk synchronously across three AZs so a pod can reschedule to another zone without losing its data.
3. Security Best Practices
Use Workload Identity (pod-level Azure RBAC)
Never put Azure credentials in pods. Use Workload Identity to give individual pods an Azure AD identity with scoped RBAC permissions:
# Enable workload identity on ARO clusteraz aro update \ --resource-group rg-aro \ --name aro-prod \ --enable-managed-identity# Create a managed identity for a specific workloadaz identity create \ --resource-group rg-aro-workloads \ --name id-payment-service# Grant it only what it needsaz role assignment create \ --assignee <identity-client-id> \ --role "Key Vault Secrets User" \ --scope /subscriptions/.../vaults/kv-prod
# Annotate the service accountapiVersion: v1kind: ServiceAccountmetadata: name: payment-service-sa namespace: payments annotations: azure.workload.identity/client-id: "<managed-identity-client-id>"
Integrate Azure Key Vault for secrets via CSI driver
Never store secrets in OpenShift Secrets (base64 is not encryption). Use the Secrets Store CSI driver to mount Key Vault secrets directly into pods:
apiVersion: secrets-store.csi.x-k8s.io/v1kind: SecretProviderClassmetadata: name: azure-kv-secrets namespace: paymentsspec: provider: azure parameters: usePodIdentity: "false" clientID: "<managed-identity-client-id>" keyvaultName: kv-prod tenantID: "<tenant-id>" objects: | array: - | objectName: db-connection-string objectType: secret - | objectName: api-key objectType: secret
Integrate with Azure Container Registry via private endpoint
# Create ACR with private endpoint — no public accessaz acr create \ --resource-group rg-aro \ --name acrprodaro \ --sku Premium \ --public-network-enabled false# Private endpoint in ARO spokeaz network private-endpoint create \ --name pe-acr-prod \ --resource-group rg-aro-network \ --vnet-name aro-spoke-vnet \ --subnet private-endpoint-subnet \ --private-connection-resource-id $(az acr show --name acrprodaro --query id -o tsv) \ --group-id registry \ --connection-name pe-acr-conn# Grant ARO pull accessaz role assignment create \ --assignee <aro-kubelet-identity> \ --role AcrPull \ --scope $(az acr show --name acrprodaro --query id -o tsv)
Apply OpenShift Security Context Constraints (SCC)
Never run pods as root. Use the restricted-v2 SCC (default in OpenShift 4.11+):
apiVersion: v1kind: Podspec: securityContext: runAsNonRoot: true runAsUser: 1001 seccompProfile: type: RuntimeDefault containers: - name: app securityContext: allowPrivilegeEscalation: false capabilities: drop: ["ALL"] readOnlyRootFilesystem: true
Enable Microsoft Defender for Containers
az security pricing create \ --name Containers \ --tier Standard
Defender for Containers provides runtime threat detection, vulnerability scanning for images in ACR, and Kubernetes audit log analysis — all surfaced in Microsoft Defender for Cloud.
4. Observability Best Practices
Forward logs to Azure Monitor / Log Analytics
# Enable container insights on AROaz aro update \ --resource-group rg-aro \ --name aro-prod \ --enable-managed-identity# Deploy the monitoring add-on via Helmhelm repo add microsoft https://microsoft.github.io/charts/repohelm install azuremonitor-containers \ microsoft/azuremonitor-containers \ --set omsagent.secret.wsid=<workspace-id> \ --set omsagent.secret.key=<workspace-key> \ --namespace kube-system
Use Azure Monitor alerts for cluster health
| Alert | Metric | Threshold |
|---|---|---|
| Node CPU pressure | cpuUsageNanoCores | > 85% for 5 min |
| Node memory pressure | memoryWorkingSetBytes | > 80% of capacity |
| Pod restart loop | restartCount | > 5 in 10 min |
| PVC near full | pvUsedBytes | > 85% of capacity |
| Node not ready | nodeCondition | NotReady > 2 min |
5. Day-2 Operations Best Practices
Cluster upgrade strategy
ARO manages the control plane upgrade automatically — you control timing for worker nodes:
# Check available upgrade versionsaz aro get-upgrade-versions \ --resource-group rg-aro \ --name aro-prod# Schedule upgrade in maintenance windowaz aro update \ --resource-group rg-aro \ --name aro-prod \ --version 4.14.12
Use the EUS (Extended Update Support) channel for production clusters — it allows staying on a minor version for up to 18 months while still receiving security patches, avoiding the churn of mandatory minor version upgrades every 45 days.
Worker node upgrade — use surge capacity
# MachineConfigPool surge upgrade strategyapiVersion: machineconfiguration.openshift.io/v1kind: MachineConfigPoolmetadata: name: workerspec: maxUnavailable: 1 # Upgrade one node at a time
Upgrade workers one node at a time to maintain application availability — pods are gracefully drained before each node reboots into the new RHCOS version.
Summary — ARO Best Practice Checklist
| Category | Practice |
|---|---|
| Network | Private cluster — no public API or ingress |
| Network | Egress via Azure Firewall with FQDN allow-list |
| Network | DNS Private Resolver for private endpoint resolution |
| Network | Worker subnet /22 or larger — never resize after |
| Availability | Workers spread across AZs via 3 MachineSets |
| Availability | Cluster autoscaler min 3 per zone |
| Availability | Premium_ZRS disks for stateful workloads |
| Availability | Zone-redundant Azure Load Balancer |
| Security | Workload Identity — no credentials in pods |
| Security | Key Vault + CSI driver — no base64 secrets |
| Security | ACR via private endpoint — no public pull |
| Security | SCC restricted-v2 — no root containers |
| Security | Defender for Containers enabled |
| Observability | Container Insights → Log Analytics |
| Observability | Azure Monitor alerts on node and pod health |
| Operations | EUS channel for production stability |
| Operations | maxUnavailable: 1 for worker upgrades |
