Step-by-step: n8n + Azure + Vector DB RAG
1. Ingest documents into Azure
Your PDFs and docs are uploaded to Azure Data Lake Storage Gen2, then processed by Azure Data Factory or Databricks to clean and split the text into chunks:
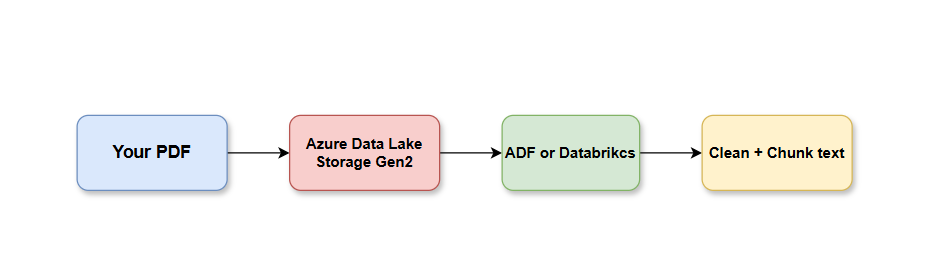
PDFs / Docs ↓Azure Data Lake Storage Gen2 ↓Azure Data Factory or Databricks ↓Clean + chunk text
Chunk example:
{ "chunk_id": "refund_policy_001", "text": "Refunds are available within 30 days...", "source": "refund_policy.pdf"}
2. Generate embeddings
Use Azure OpenAI embeddings.
Each text chunk is passed through Azure OpenAI’s embedding model to convert it into a vector (a list of numbers representing meaning). The article notes that the same embedding model must be used for both document chunks and user queries — otherwise similarity search won’t work correctly.
Chunk text → Azure OpenAI Embedding Model → Vector
Azure AI Search recommends using the same embedding model for document embeddings and query embeddings. (GitHub)
3. Store vectors in Azure AI Search
Create an Azure AI Search vector index with fields like:
The vectors are stored in an Azure AI Search vector index with fields like chunk_id, text, source, embedding_vector, and metadata. This becomes your searchable knowledge base
chunk_idtextsourceembedding_vectormetadata
Azure AI Search supports vector indexes, vector fields, and vector search configurations. (Microsoft Learn)
4. Build the n8n workflow
In n8n:
Webhook Trigger ↓Azure OpenAI Embedding HTTP Request ↓Azure AI Search Vector Query HTTP Request ↓Code Node: Format Retrieved Context ↓Azure OpenAI Chat Completion ↓Respond to Webhook
n8n’s HTTP Request node can call external REST APIs with methods, headers, and request bodies. (n8n)
5. Webhook receives user question
Example request:
{ "question": "What is the refund policy?"}
6. n8n calls Azure OpenAI embedding endpoint
Use an HTTP Request node:
POST https://YOUR-AZURE-OPENAI.openai.azure.com/openai/deployments/YOUR-EMBEDDING-DEPLOYMENT/embeddings?api-version=...
Headers:
api-key: YOUR_AZURE_OPENAI_KEYContent-Type: application/json
Body:
{ "input": "{{ $json.question }}"}
7. n8n searches Azure AI Search
Use another HTTP Request node:
POST https://YOUR-SEARCH-SERVICE.search.windows.net/indexes/YOUR-INDEX/docs/search?api-version=...
Body idea:
{ "vectorQueries": [ { "kind": "vector", "vector": "{{ embedding_from_previous_node }}", "fields": "embedding_vector", "k": 5 } ], "select": "chunk_id,text,source"}
Azure provides REST samples for creating vector indexes, loading embeddings, and running vector/hybrid queries. (Microsoft Learn)
8. Format retrieved chunks
n8n Code Node:
const context = items .map(item => `Source: ${item.json.source}\nText: ${item.json.text}`) .join("\n\n");return [ { json: { question: $node["Webhook"].json.question, context } }];
9. Send grounded prompt to Azure OpenAI
Prompt:
You are an internal AI assistant.Answer only using the provided context.If the answer is not in the context, say you don't know.Include sources.Context:{{ $json.context }}Question:{{ $json.question }}
10. Return answer to user
{ "answer": "Refunds are available within 30 days.", "sources": ["refund_policy.pdf"]}
Interview-ready explanation
“Azure handles storage, embedding, indexing, and retrieval. n8n acts as the orchestration layer. It receives the user query, generates a query embedding through Azure OpenAI, searches Azure AI Search for similar document chunks, builds a grounded prompt, calls the LLM, and returns an answer with citations.”
Why This Architecture Is Powerful
Layer Tool Role Storage Azure Data Lake Holds raw documents Processing Azure Data Factory Cleans & chunks text Embeddings Azure OpenAI Converts text → vectors Search Azure AI Search Finds relevant chunks Orchestration n8n Connects all the pieces LLM Azure OpenAI Chat Generates the answer
This is a production-grade RAG pipeline built without writing a full application — n8n’s HTTP Request nodes call Azure REST APIs directly, so you get the full power of Azure AI services orchestrated visually. The answer is always grounded in your actual documents, with sources cited, which eliminates hallucination on company-specific knowledge.
