my notes for aws Certified Solutions Architect – Associate – exam
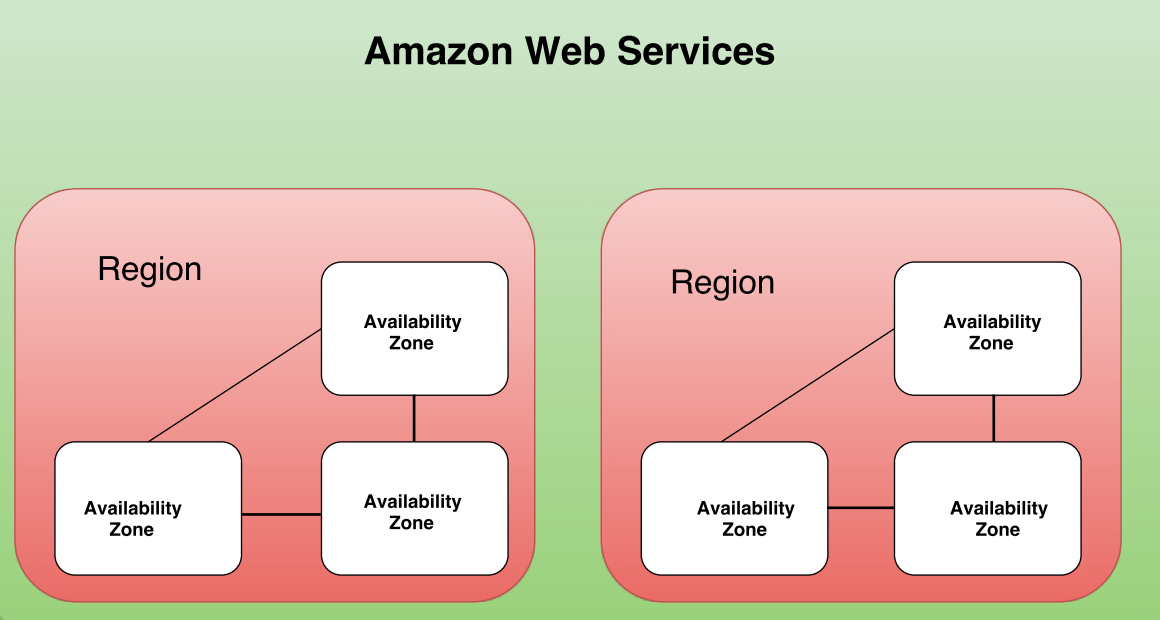
Regions
Each region is completely independent. Each Availability Zone is isolated, but the Availability Zones in a region are connected through low-latency links. The following diagram illustrates the relationship between regions and Availability Zones.

Edge Locations are used in conjunction with the AWS CloudFront service which is Content Delivery Network service. Edge Locations are deployed across the world in multiple locations to reduce latency for traffic served over the CloudFront and as result are usually located in highly populated areas.
1. SECURITY
IAM – Identity Access Management
-With IAM, you can centrally manage users, security credentials such as passwords, access keys, and permissions policies that control which AWS services and resources users can access
-You can use IAM to securely control individual and group access to your AWS resources.
-Currently, IAM users can use their SSH keys only with AWS CodeCommit to access their repositories.
– AWS supports the Security Assertion Markup Language (SAML) 2.0.
-IAM users can have any combination of credentials that AWS supports, such as an AWS access key, X.509 certificate, SSH key, password for web app logins, or an MFA device
- You can not apply a rolle to a running instance, can only be applied at instance lunch
* Identity Federation
You can allow users who already have password elsewhere –
You can also grant permissions for users outside of AWS (federated users).
– AWS Identity and Access Management (IAM) supports identity federation for delegated access to the AWS Management Console or AWS APIs. With identity federation, external identities are granted secure access to resources in your AWS account without having to create IAM users. These external identities can come from your corporate identity provider (such as Microsoft Active Directory or from the AWS Directory Service) or from a web identity provider (such as Amazon Cognito, Login with Amazon, Facebook, Google, or any OpenID Connect-compatible provider).
Multi-Factor Authentication
AWS-MFA provides an extra level of security that you can apply to your AWS environment.
AWS multi-factor authentication (AWS MFA) provides an extra level of security that you can apply to your AWS environment. You can enable AWS MFA for your AWS account and for individual AWS Identity and Access Management (IAM) users you create under your account.
– Hardware MFA device
– Virtual MFA device
**Identity Providers and Federation
If you already manage user identities outside of AWS, you can use IAM identity providers instead of creating IAM users in your AWS account. With an identity provider (IdP), you can manage your user identities outside of AWS and give these external user identities permissions to use AWS resources in your account. This is useful if your organization already has its own identity
system, such as a corporate user directory. It is also useful if you are creating a mobile app or web application that requires access to AWS resources.
*** IAM Role management
An IAM role is an IAM entity that defines a set of permissions for making AWS service requests
– You can only associate an IAM role while launching an EC2 instance
**** Temporary Security Credentials
**** Identity Federation
AWS Identity and Access Management (IAM) supports identity federation for delegated access to the AWS Management Console or AWS APIs. With identity federation, external identities are granted secure access to resources in your AWS account without having to create IAM users. These external identities can come from your corporate identity provider (such as Microsoft Active Directory or from the AWS Directory Service) or from a web identity provider (such as Amazon Cognito, Login with Amazon, Facebook, Google, or any OpenID Connect-compatible provider)
AWS CloudHSM
-The AWS CloudHSM service helps you meet corporate, contractual and regulatory compliance requirements for data security by using dedicated Hardware Security Module (HSM) appliances within the AWS cloud
-A Hardware Security Module (HSM) is a hardware appliance that provides secure key storage and cryptographic operations within a tamper-resistant hardware device
AWS Directory Service
AWS Key Management Service
AWS AWF
AWS WAF is a web application firewall that helps protect web applications from attacks by allowing you to configure rules that allow, block, or monitor (count) web requests based on conditions that you define. These conditions include IP addresses, HTTP headers, HTTP body, URI strings, SQL injection and cross-site scripting.
2. STORAGE
AWS Object Storage and CDN, S3 , Glacier and Cloud front
*Amazon simple storage service (s3)*
Amazon S3 is storage for the Internet. It’s a simple storage service that offers software developers a highly-scalable, reliable, and low-latency data storage infrastructure at very low costs.
Amazon S3 is secure by default. Only the bucket and object owners originally have access to Amazon S3 resources they create. Amazon S3 supports user authentication to control access to data. You can use access control mechanisms such as bucket policies and Access Control Lists (ACLs) to selectively grant permissions to users and groups of users. You can securely upload/download your data to Amazon S3 via SSL endpoints using the HTTPS protocol. If you need extra security you can use the Server Side Encryption (SSE) option or the Server Side Encryption with Customer-Provide Keys (SSE-C) option to encrypt data stored-at-rest. Amazon S3 provides the encryption technology for both SSE and SSE-C. Alternatively you can use your own encryption libraries to encrypt data before storing it in Amazon S3.
** Data Protection **
Amazon S3 Standard and Standard – IA are designed to provide 99.999999999% durability of objects over a given year. This durability level corresponds to an average annual expected loss of 0.000000001% of objects. For example, if you store 10,000 objects with Amazon S3, you can on average expect to incur a loss of a single object once every 10,000,000 years. In addition, Amazon S3 is designed to sustain the concurrent loss of data in two facilities.
Amazon S3 buckets in all Regions provide read-after-write consistency for PUTS of new objects and eventual consistency for overwrite PUTS and DELETES.
As with any environments, the best practice is to have a backup and to put in place safeguards against malicious or accidental users errors. For S3 data, that best practice includes secure access permissions, Cross-Region Replication, versioning and a functioning, regularly tested backup.
*** Versioning
Versioning allows you to preserve, retrieve, and restore every version of every object stored in an Amazon S3 bucket. Once you enable Versioning for a bucket, Amazon S3 preserves existing objects anytime you perform a PUT, POST, COPY, or DELETE operation on them. By default, GET requests will retrieve the most recently written version. Older versions of an overwritten or deleted object can be retrieved by specifying a version in the request.
Versioning offers an additional level of protection by providing a means of recovery when customers accidentally overwrite or delete objects.
Amazon S3 Standard – Infrequent Access (Standard – IA) is an Amazon S3 storage class for data that is accessed less frequently, but requires rapid access when needed.
Standard – IA offers the high durability, throughput, and low latency of Amazon S3 Standard, with a low per GB storage price and per GB retrieval fee. This combination of low cost and high performance make Standard – IA ideal for long-term storage, backups, and as a data store for disaster recovery. The Standard – IA storage class is set at the object level and can exist in the same bucket as Standard, allowing you to use lifecycle policies to automatically transition objects between storage classes without any application changes.
Standard – IA is ideal for data that is accessed less frequently, but requires rapid access when needed. Standard – IA is ideally suited for long-term file storage, older data from sync and share, backup data, and disaster recovery files.
S3 Standard – Infrequent Access provide the same performance as S3 Standard storage.
**Glacier**
Glacier – storage for data archival
*** S3 – security
The valid ways of encrypting data on S3 are:
–Server Side Encryption (SSE)-S3,SSE-C, SSE-KMS or a client library such as Amazon S3 Encryption Client.
-Amazon S3 is secure by default. Only the bucket and object owners originally have access to Amazon S3 resources they create
– You can use bucket policies & Acess Control Lists (ACLs) to selectively
grant permissions to user and groups of users
– if you need extra security you can use Server Side Encryption (SSE ) or
**Control access –
There are a number of different options available to restrict access to S3 objects,
four mechanisms for controlling access to Amazon S3
-IAM policy
-bucket policies
-Access Control Lists( ACLS)
-query string authentication
**CCR Cross – Region Replication **
CRR is an Amazon S3 feature that automatically replicates data across AWS regions. With CRR, every object uploaded to an S3 bucket is automatically replicated to a destination bucket in a different AWS region that you choose. You can use CRR to provide lower-latency data access in different geographic regions. CRR can also help if you have a compliance requirement to store copies of data hundreds of miles apart.
– CRR is a bucket-level configuration. You enable a CRR configuration on your source bucket by specifying a destination bucket in a different region for replication
Workloads
The Amazon S3 best practice guidance given in this topic is based on two types of workloads:
- Workloads that include a mix of request types – If your requests are typically a mix of GET, PUT, DELETE, or GET Bucket (list objects), choosing appropriate key names for your objects will ensure better performance by providing low-latency access to the Amazon S3 index. It will also ensure scalability regardless of the number of requests you send per second.
- Workloads that are GET-intensive – If the bulk of your workload consists of GET requests, we recommend using the Amazon CloudFront content delivery service.
Integrating Amazon CloudFront with Amazon S3, you can distribute content to your users with low latency and a high data transfer rate. You will also send fewer direct requests to Amazon S3, which will reduce your costs
size – a minimum of 0 bytes to a maximum of 5 terabytes
-The largest object that can be uploaded in a single PUT is 5 Gigabytes
-for Objects larger than 100 megabytes, customers should consider using a multipart upload capability
-You can use Multi-Object Delete to delete large numbers of objects from Amazon S3. This feature allows you to send multiple object keys in a single request to speed up your deletes. Amazon does not charge you for using Multi-Object Delete.
– By default, customers can provision up to 100 buckets per AWS account
– Amazon S3 is secure by default. Only the bucket and object owners originally have access to Amazon S3 resources they create
– You can choose to encrypt data using SSE-S3, SSE-C, SSE-KMS, or a client library such as the Amazon S3 Encryption Client
** S3 is a object based storage ( for files only )
** File can be from 1 byte to 5 TB
** unlimited storage
** Files are stored in buckets
|** S3 is universal name space , name must be unique globally
** Read after write consistency for PUTS of new objects
** Eventual consistency for overwrite PUTS and DELETES
** S3 Classes
- S3 – durable, immediately available, frequently access
- S3 – IA – durable, immediately available, infrequent access
- S3- Reduce Redundancy Storage
- Glacier
An Amazon VPC Endpoint for Amazon S3 is a logical entity within a VPC that allows connectivity only to S3. The VPC Endpoint routes requests to S3 and routes responses back to the VPC. For more information about VPC Endpoints, read Using VPC Endpoints.
*Amazon Elastick Block Store (Amazon EBS)*
Amazon Elastic Block Store (Amazon EBS) provides persistent block level storage volumes for use with Amazon EC2 instances in the AWS Cloud. Each Amazon EBS volume is automatically replicated within its Availability Zone to protect you from component failure, offering high availability and durability. Amazon EBS volumes offer the consistent and low-latency performance needed to run your workloads. With Amazon EBS, you can scale your usage up or down within minutes – all while paying a low price for only what you provision
Amazon EBS provides three volume types:
-General Purpose (SSD) volumes
- IOPS baseline : 100-10,000
- IOPS Burst: 30 minutes @ 3,000
- Latency : single digit ms
- Performance Consistency: 99%
- Most workloads
-Provisioned IOPS (SSD) volumes
- IOPS: 100-20,000
- Throughput: Up to 320 MB/s
- Latency : single digit ms
- Performance Consistency: 99.9%
- Mission Critical
-Magnetic volumes.
- IOPS : typically 100
- Throughput: 40-90 MB/s
- Latency : Read 10-40ms, Write 2-10ms
- Best for infrequently access data
These volume types differ in performance characteristics and price, allowing you to tailor your storage performance and cost to the needs of your applications. For more performance infomation see the EBS product details page.
– snapshots are only available through the Amazon EC2 APIs.
EBS – summary
-A block storage (so you need to format it).
-As it’s a block storage, you can use Raid 1 (or 0 or 10) with multiple block storages
– It is really fast and is relatively cheap
– You can snapshot an EBS (while it’s still running) for backup reasons
– cannot just access it across regions
– You need an EC2 instance to attach it
-99.999% availability
With Amazon EBS, you can use any of the standard RAID configurations that you can use with a traditional bare metal server, as long as that particular RAID configuration is supported by the operating system for your instance. This is because all RAID is accomplished at the software level. For greater I/O performance than you can achieve with a single volume, RAID 0 can stripe multiple volumes together; for on-instance redundancy, RAID 1 can mirror two volumes together.
Amazon EBS volume data is replicated across multiple servers in an Availability Zone to prevent the loss of data from the failure of any single component. This replication makes Amazon EBS volumes ten times more reliable than typical commodity disk drives. For more information, see Amazon EBS Availability and Durability in the Amazon EBS product detail pages.
Creating a RAID 0 array allows you to achieve a higher level of performance for a file system than you can provision on a single Amazon EBS volume. A RAID 1 array offers a “mirror” of your data for extra redundancy. Before you perform this procedure, you need to decide how large your RAID array should be and how many IOPS you want to provision.
The resulting size of a RAID 0 array is the sum of the sizes of the volumes within it, and the bandwidth is the sum of the available bandwidth of the volumes within it. The resulting size and bandwidth of a RAID 1 array is equal to the size and bandwidth of the volumes in the array. For example, two 500 GiB Amazon EBS volumes with 4,000 provisioned IOPS each will create a 1000 GiB RAID 0 array with an available bandwidth of 8,000 IOPS and 640 MB/s of throughput or a 500 GiB RAID 1 array with an available bandwidth of 4,000 IOPS and 320 MB/s of throughput.
** EBS – snapshot **
There is a limit of 5 pending snapshots for a single volume.
-Snapshot that are taken from encrypted volume s are automatically encrypted
– To create a snapshot for Amazon EBS volumes that serve as root devices, you should stop the instance before taking the snapshot.
– Instances store Volumes are sometime called Ephemeral Storage
– Instances store Volumes can not be stooped
– EBS baked instance can be stooped. You will not lose the data of this instance if is stopped
-You can reboot both, you will not lose the your data
-By default, both ROOT volumes will be delete on termination , with EBS you can tell AWS to keep the root volume
** Volume restore from snapshots
CLI
aws ec2 create-snapshot –volume-id vol-123abc –description ” this is a snapshot”
*Amazon Cloud Front*
Amazon CloudFront is a global content delivery network (CDN) service. It integrates with other Amazon Web Services products to give developers and businesses an easy way to distribute content to end users with low latency, high data transfer speeds, and no minimum usage commitments.
*Amazon Glacier*
– an extremely low cost storage service that provides highly secure, durable, and flexible storage for data backup and archival
Amazon Glacier is a low cost storage service designed to store data that is infrequently accessed and long lived. Amazon Glacier jobs typically complete in 3 to 5 hours
**Cross Region Replication – CCR**
CRR is an Amazon S3 feature that automatically replicates data across AWS regions. With CRR, every object uploaded to an S3 bucket is automatically replicated to a destination bucket in a different AWS region that you choose. You can use CRR to provide lower-latency data access in different geographic regions. CRR can also help if you have a compliance requirement to store copies of data hundreds of miles apart
*AWS Import/Export Snowball*
A single Snowball appliance can transport up to 50 terabytes of data and multiple appliances can be used in parallel to transfer petabytes of data into or out of AWS
*AWS Storage Gateway*
The AWS Storage Gateway supports three configurations:
Gateway-Cached Volumes: You can store your primary data in Amazon S3, and retain your frequently accessed data locally. Gateway-cached volumes provide substantial cost savings on primary storage, minimize the need to scale your storage on-premises, and retain low-latency access to your frequently accessed data.
Gateway-Stored Volumes: In the event you need low-latency access to your entire data set, you can configure your on-premises data gateway to store your primary data locally, and asynchronously back up point-in-time snapshots of this data to Amazon S3. Gateway-stored volumes provide durable and inexpensive off-site backups that you can recover locally or from Amazon EC2 if, for example, you need replacement capacity for disaster recovery.
Gateway-Virtual Tape Library (VTL): With gateway-VTL you can have a limitless collection of virtual tapes. Each virtual tape can be stored in a Virtual Tape Library backed by Amazon S3 or a Virtual Tape Shelf (VTS) backed by Amazon Glacier. The Virtual Tape Library exposes an industry standard iSCSI interface which provides your backup application with on-line access to the virtual tapes. When you no longer require immediate or frequent access to data contained on a virtual tape, you can use your backup application to move it from its Virtual Tape Library to your Virtual Tape Shelf in order to further reduce your storage costs.
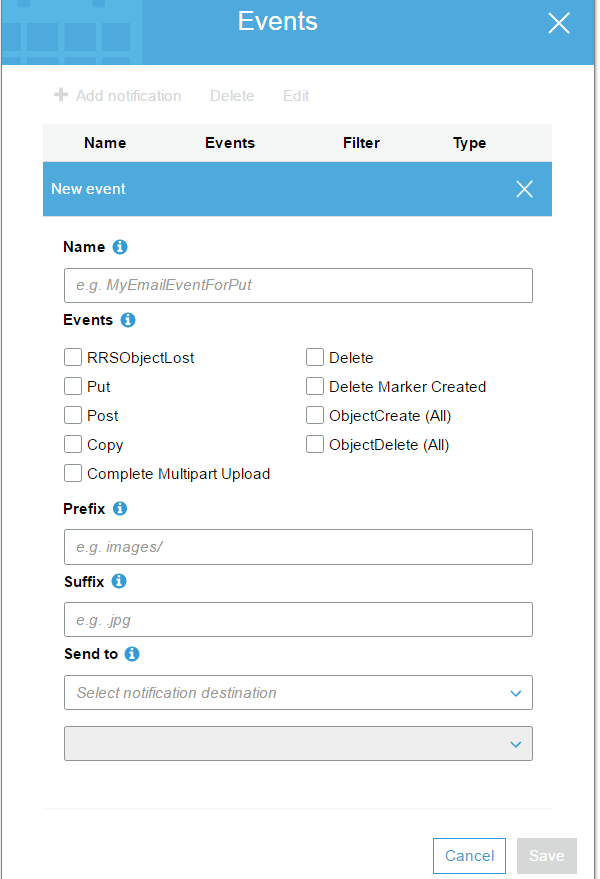
** Event Notification **
EC2
Amazon Elastic Compute Cloud ( Amazon EC2 ) is a web services that provides resizable compute capacity in the cloud
Amazon EC2 provides a wide selection of instance types optimized to fit different use cases. Instance types comprise varying combinations of CPU, memory, storage, and networking capacity and give you the flexibility to choose the appropriate mix of resources for your applications
Amazon ec2 instance type
T2 – General Purpose
t2.nano, t2.micro, t2.small, t2.medium, t2.large
Storage – EBS only
T2 instances work well with Amazon EBS General purpose (SSD) volumes for instance block storage
M4 – are the latest generation of General Purpose
Storage – EBS only
M3 –
SSD – storage
Use Cases
Small and mid-size databases, data processing tasks that require additional memory, caching fleets, and for running backend servers for SAP, Microsoft SharePoint, cluster computing, and other enterprise applications.
C4 –
Model vCPU Mem(GiB) Storage Throughput(Mbps)
c4.large 2 3.75 EBS-Only 500
c4.xlarge 4 7.5 EBS-Only 750
c4.2xlarge 8 15 EBS-Only 1,000
c4.4xlarge 16 30 EBS-Only 2,000
c4.8xlarge 36 60 EBS-Only 4,000
C3 –
c3.large – 2 vCPU
c3.xlarge, 4 vCPU
c3.2xlarge – 8 vCPU
c3.4xlarge – 16 vCPU
c3.8xlarge – 32 vCPU
Use Cases
High performance front-end fleets, web-servers, batch processing, distributed analytics, high performance science and engineering applications, ad serving, MMO gaming, and video-encoding.
R3 – Memory Optimized
R3 instances are optimized for memory-intensive applications and have the lowest cost per GiB of RAM among Amazon EC2 instance types.
G2 – GPU
This family includes G2 instances intended for graphics and general purpose GPU compute applications
I2 – storage Optimized High I/O instances
This family includes the High Storage Instances that provide very fast SSD-backed instance storage optimized for very high random I/O performance, and provide high IOPS at a low cost.
D2 – Dense- storage instances
D2 instances feature up to 48 TB of HDD-based local storage, deliver high disk throughput, and offer the lowest price per disk throughput performance on Amazon EC2.
Amazon EC2 allows you to choose between Fixed Performance Instances (e.g. M3, C3, and R3) and Burstable Performance Instances (e.g. T2). Burstable Performance Instances provide a baseline level of CPU performance with the ability to burst above the baseline. T2 instances are for workloads that don’t use the full CPU often or consistently, but occasionally need to burst.
EC2 compute unit
***Spot instance
Spot instances are a new way to purchase and consume Amazon EC2 Instances. They allow customers to bid on unused EC2 capacity and run those instances for as long as their bid exceeds the current Spot Price. The Spot Price changes periodically based on supply and demand, and customers whose bids meet or exceed it gain access to the available Spot instances. Spot instances are complementary to On-Demand instances and Reserved Instances, providing another option for obtaining compute capacity.
EC2 – placement group
*Elastic IP*
An Elastic IP address is a static IP address designed for dynamic cloud computing. An Elastic IP address is associated with your AWS account. With an Elastic IP address, you can mask the failure of an instance or software by rapidly remapping the address to another instance in your account.
An Elastic IP address is a public IP address, which is reachable from the Internet. If your instance does not have a public IP address, you can associate an Elastic IP address with your instance to enable communication with the Internet; for example, to connect to your instance from your local computer
By default, all accounts are limited to 5 Elastic IP addresses per region. If you need more the 5 Elastic IP addresses, we ask that you apply for your limit to be raised
*Elastic Load Balancing*
Elastic Load Balancing automatically distributes incoming application traffic across multiple Amazon EC2 instances in the cloud. It enables you to achieve greater levels of fault tolerance in your applications, seamlessly providing the required amount of load balancing capacity needed to distribute application traffic.
-Elastic Load Balancing supports load balancing of applications using HTTP, HTTPS (Secure HTTP), SSL (Secure TCP) and TCP protocols.
– you can map HTTP port 80 and HTTPS port 443 to a single Elastic Load Balancer.
– To receive a history of Elastic Load Balancing API calls made on your account, simply turn on CloudTrail in the AWS Management Console
** Configure the Idle time out **
For each request that a client makes through a load balancer, the load balancer maintains two connections. One connection is with the client and the other connection is to a back-end instance . For each connection, the load balancer manage an idle time out that is triggered when no data is sent over the connection for a specified time period
**Configure Coss-Zone Load Balancing
By default, your load balancer distributes incoming requests evenly across its enabled Availability Zones.
Cross-Zone load balancing reduce the needs to maintain equivalent numbers of back-end instances in each Availability Zones, and improves our application’s ability to handle the loss of one or more instances
** Configure Connection Draining for ELB **
To ensure that the load balancer stops sending request to instance that are de-registering or unhealthy, while keeping the existing connection open, use connection draining . This enable the load balancer to complete in -flight requests made to instances that are de-register or unhealthy.
** Configure Sticky Sesions **
By default, a load balancer routes each request independently to the registered instance with the smallest load . However, you can use sticky session feature ( also know as session affinity ) which enable the load balancer to bind the user’s session to a specific instance . This ensures that all requests from the user during the session are sent to the same instance
AWS Elastic Beanstalk
AWS Elastic Beanstalk is an easy-to-use service for deploying and scaling web applications and services developed with Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker on familiar servers such as Apache, Nginx, Passenger, and IIS.
You can simply upload your code and Elastic Beanstalk automatically handles the deployment, from capacity provisioning, load balancing, auto-scaling to application health monitoring. At the same time, you retain full control over the AWS resources powering your application and can access the underlying resources at any time.
There is no additional charge for Elastic Beanstalk – you pay only for the AWS resources needed to store and run your applications.
* Amazon CloudWatch*
-Amazon CloudWatch is a monitoring service for AWS cloud resources and the applications you run on AWS. You can use Amazon CloudWatch to collect and track metrics, collect and monitor log files, and set alarms. Amazon CloudWatch can monitor AWS resources such as Amazon EC2 instances, Amazon DynamoDB tables, and Amazon RDS DB instances, as well as custom metrics generated by your applications and services, and any log files your applications generate. You can use Amazon CloudWatch to gain system-wide visibility into resource utilization, application performance, and operational health. You can use these insights to react and keep your application running smoothly.
-Many metrics are received and aggregated at 1-minute intervals. Some are at 3-minute or 5-minute intervals.
-Minimal time interval- Metrics are received and aggregated at 1 minute intervals.
-When you create an alarm, you can configure it to perform one or more automated actions when the metric you chose to monitor exceeds a threshold you define. For example, you can set an alarm that sends you an email, publishes to an SQS queue, stops or terminates an Amazon EC2 instance, or executes an Auto Scaling policy.
Since Amazon CloudWatch alarms are integrated with Amazon Simple Notification Service, you can also use any notification type supported by SNS.
– You can retrieve metrics data for any Amazon EC2 instance up to 2 weeks from the time you started to monitor it. After 2 weeks, metrics data for an Amazon EC2 instance will not be available if monitoring was disabled for that Amazon EC2 instance
monitor EC2 Instance
View metrics for CPU utilization, data transfer, and disk usage activity from Amazon EC2 instances (Basic Monitoring) for no additional charge. For an additional charge, CloudWatch provides Detailed Monitoring for EC2 instances with higher resolution and metric aggregation. No additional software needs to be installed.
Monitor EC2 instances automatically, without installing additional software:
- Basic Monitoring for Amazon EC2 instances: Seven pre-selected metrics at five-minute frequency and three status check metrics at one-minute frequency, for no additional charge.
- Detailed Monitoring for Amazon EC2 instances: All metrics available to Basic Monitoring at one-minute frequency, for an additional charge. Instances with Detailed Monitoring enabled allows data aggregation by Amazon EC2 AMI ID and instance type.
-You can use the CLI to retrieve your log events and search through them using command line grep or similar search functions.
CloudWatch – CLI -example
Delete alarms
$ aws cloudwatch delete-alarms –alarm-name myalarm
The following example uses the list-metrics command to list the metrics for Amazon SNS
$aws cloudwatch list-metrics –namespace “AWS/SNS”
*ELB
Elastic Load-Balancing
-Timeout Configuration
-Connection Draining
-Cross-Zone Load Balancing
*Autoscaling*
Auto Scaling helps you maintain application availability and allows you to scale your Amazon EC2 capacity up or down automatically according to conditions you define
you can define a scale up condition to increase your Amazon EC2 capacity by 10% and a scale down condition to decrease it by 5%.
If you have an Auto Scaling group with running instances and you choose to delete the Auto Scaling group, the instances will be terminated and the Auto Scaling group will be deleted.
auto scaling instance state
Instances in Auto Scaling group can be in one of four main states
** Pending
** InService
** Terminating
** Terminated
autoscaling – cli
* Reserved instances
Spot Instances
Micro Instances
Compute-Optimized Instances
GPU – instances
Cluster Instances
High I/O instances
** VM Import/Export
You can import your VM images using the Amazon EC2 API tools:
- Import the VMDK, VHD or RAW file via the ec2-import-instance API. The import instance task captures the parameters necessary to properly configure the Amazon EC2 instance properties (instance size, Availability Zone, and security groups) and uploads the disk image into Amazon S3.
- If ec2-import-instance is interrupted or terminates without completing the upload, use ec2-resume-import to resume the upload. The import task will resume where it left off.
- Use the ec2-describe-conversion-tasks command to monitor the import progress and obtain the resulting Amazon EC2 instance ID.
- Once your import task is completed, you can boot the Amazon EC2 instance by specifying its instance ID to the ec2-run-instances API.
- Finally, use the ec2-delete-disk-image command line tool to delete your disk image from Amazon S3 as it is no longer needed.
Availability Zones
Databases on AWS
*RDS
*DynamoDB
*Elasticache*
Elasticache is a web service that makes it easy to deploy, operate, and scale a distributed, in-memory cache in the cloud. ElastiCache improves the performance of web applications by allowing you to retrieve information from afast, managed, in-memory caching system, instead of relying entirely on slower disk-based databases. ElastiCache supports two popular open-source caching engines: Memcached and Redis.
Memcached –ElastiCache is protocol-compliant with Memcached, a widely adopted memory object caching system, so code, applications, and popular tools that you use today with existing Memcached environments will work seamlessly with the service.
Redis –a popular open-source in-memory key-value store that supports data structures such as sorted sets and lists.
ElastiCache supports Redismaster / slave replication which can be used to achieve cross Availability Zoneredundancy.
*Redshift*
DMS
Networking
*VPC*
A Virtual Private Cloud (VPC): A logically isolated virtual network in the AWS cloud.
Amazon VPC lets you provision a logically isolated section of the AWS cloud where you can lunch your AWS resources in a virtual network that you define.
The VPC lives within a single AWS region, but is subnets can be spread across Multiple AZ
*components of Amazon VPC
- subnet
- Internet Gateway
- NAT Gateway
- Hardware VPN connection
- Virtual Private Gateway
- Customer Gateway
- Router
- Peering Connection
- VPC Endpoint for S3:
A VPC endpoint enables you to create a private connection between your VPC and anoter AWS services withowt
Endpoints are virtual devices
Currently, Amazon S3 is the only VPC endpoint .Adding S3 as a VPC endpoint allow you to access your S3 buckets without sending request through the Internet
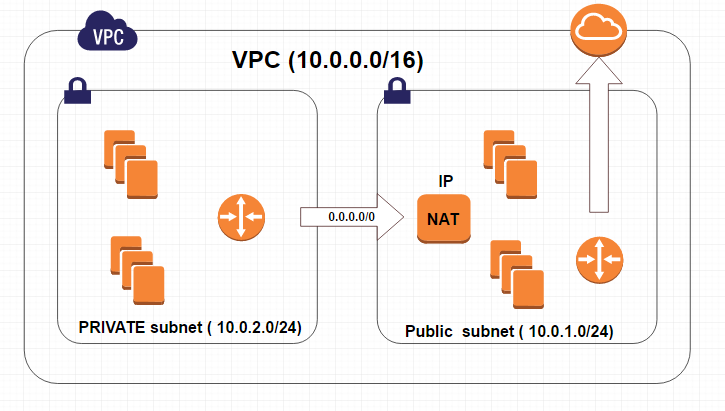
Four basic options for network architectures, The four options are:
- VPC with a Single Public Subnet Only
- VPC with Public and Private Subnets
- VPC with Public and Private Subnets and Hardware VPN Access
- VPC with a Private Subnet Only and Hardware VPN Access
The core difference between a public and private subnets is defined by what subnet’s default route is, in the VPC tables.
- The VPC’s “Internet Gateway” object, in the case of a public subnet
- an EC2 instances, performing the “NAT instance” role, in the case of private subnet
*Connectivity
You may connect your VPC to:
- The Internet (via an Internet Gateway)
- Your corporate data center using a Hardware VPN connection (via the Virtual Private Gateway)
- Both the Internet and your corporate data center (utilizing both an Internet Gateway and a Virtual Private Gateway)
- Other AWS services (via Internet Gateway, NAT, Virtual Private Gateway, or VPC Endpoints)
- Other VPCs (via VPC peering connections)
Amazon VPC supports the creation of an Internet gateway. This gateway enables Amazon EC2 instances in the VPC to directly access the Internet.
Elastic IP addresses (EIPs) give instances in the VPC the ability to both directly communicate outbound to the Internet and to receive unsolicited inbound traffic from the Internet (e.g., web servers)
Instances without EIPs can access the Internet in one of two ways:
- Instances without EIPs can route their traffic through a NAT gateway to access the Internet. These instances use the EIP of the NAT gateway to traverse the Internet. The NAT gateway allows outbound communication but doesn’t enable machines on the Internet to initiate a connection to the privately addressed machines using NAT.
- For VPCs with a hardware VPN connection, instances can route their Internet traffic down the Virtual Private Gateway to your existing datacenter. From there, it can access the Internet via your existing egress points and network security/monitoring devices.
There are two ways to create a VPC using the Amazon VPC console: the Create VPC dialog box and the VPC wizard
*IP Addressing
Currently, Amazon VPC supports VPCs between /28 (in CIDR notation) and /16 in size. The IP address range of your VPC should not overlap with the IP address ranges of your existing network.
Amazon reserves the first four (4) IP addresses and the last one (1) IP address of every subnet for IP networking purposes.
The minimum size of a subnet is a /28 (or 16 IP addresses.) Subnets cannot be larger than the VPC in which they are created.
The larges subnet use a /16 netmask ( 65,536 IP addresses )
If you create a VPC with CIDR bloc 10.0.0.0/24 – it supports 256 addresses ( – minus 5 reserved ) . You can break this CIDR block into two subnets, each supporting 128 IP addresses,
Recommended for most customers:
- /16 VPC ( 64 K addresses)
- /24 Subnets (251 addresses )
- One subnet per Availability zones
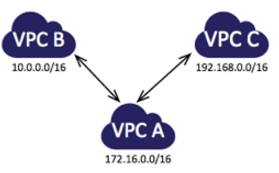
VPC peering
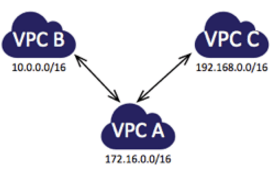
The following diagram is an example of one VPC peered to two different VPCs. There are two VPC peering connections: VPC A is peered with both VPC B and VPC C. VPC B and VPC C are not peered, and you cannot use VPC A as a transit point for peering between VPC B and VPC C. If you want to enable routing of traffic between VPC B and VPC C, you must create a unique VPC peering connection between them.
VPC Flow Logs
Routing Polocy
simple
weighted
latency
failover
geolocation
Network ACLs = Stateless firewall rules
Security groups
VPC Flow Logs: See all your traffic
- Visibility into effects of security group rules
- Troubleshooting network connectivity
- Ability to anylize traffic
VPC – cli
Create a VPC
$aws ec2 create-subnet –vpc-id vpc-a01106c2 –cidr-block 10.0.1.0/24
Delete a VPC
$ec2-delete-vpc vpc_id
Describes one or more of your VPCs.
The short version of this command is ec2dvpc
ec2-describe-vpcs [ vpc_id … ] [[–filter “name=value”] …]
*** Elastic Network Interfaces (ENI)
An elastic network interface (ENI) is a virtual network interface that you can attach to an instance in a VPC. ENIs are available only for instances running in a VPC.
- You can attach an elastic network interface to an instance when it’s running (hot attach), when it’s stopped (warm attach), or when the instance is being launched (cold attach)
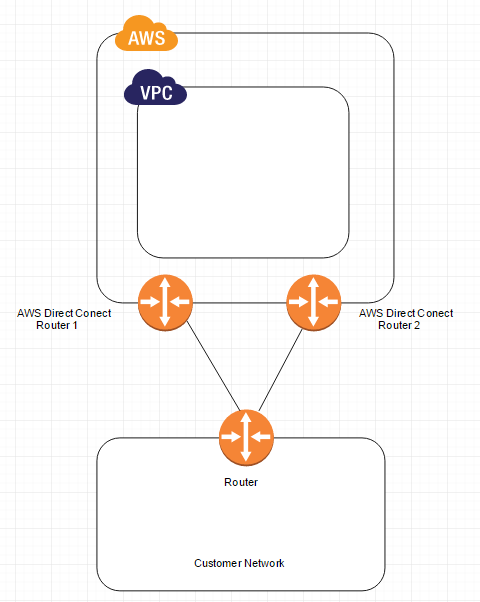
*AWS Direct Connect*
AWS Direct Connect makes it easy to establish a dedicated network connection from your premises to AWS. Using AWS Direct Connect, you can establish private connectivity between AWS and your datacenter, office, or colocation environment, which in many cases can reduce your network costs, increase bandwidth throughput, and provide a more consistent network experience than Internet-based connections.
AWS Direct Connect lets you establish a dedicated network connection between your network and one of the AWS Direct Connect locations. Using industry standard 802.1q VLANs, this dedicated connection can be partitioned into multiple virtual interfaces. This allows you to use the same connection to access public resources such as objects stored in Amazon S3 using public IP address space, and private resources such as Amazon EC2 instances running within an Amazon Virtual Private Cloud (VPC) using private IP space, while maintaining network separation between the public and private environments. Virtual interfaces can be reconfigured at any time to meet your changing needs.
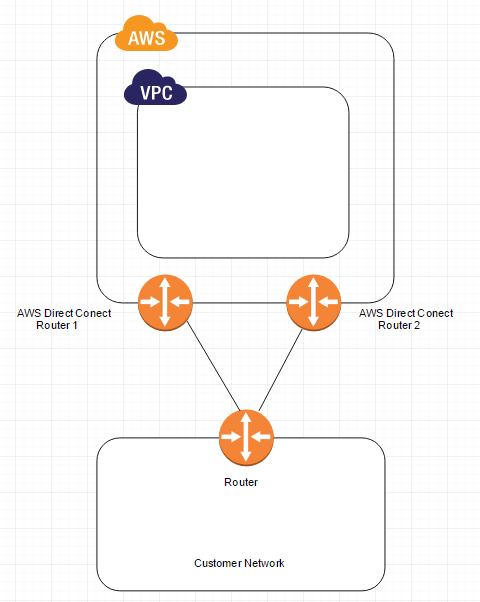
The following diagram shows a simple Direct Connect connection with a redundant paths
VPN vs Direct Connect
- Both allow secure connections between your network and your VPC
- VPN is a pair of IPSec tunnels over the Internet
- Direct Connect is a dedicated line with lower per-GB data transfer rates
- For highets availability : use both
Security & Filtering
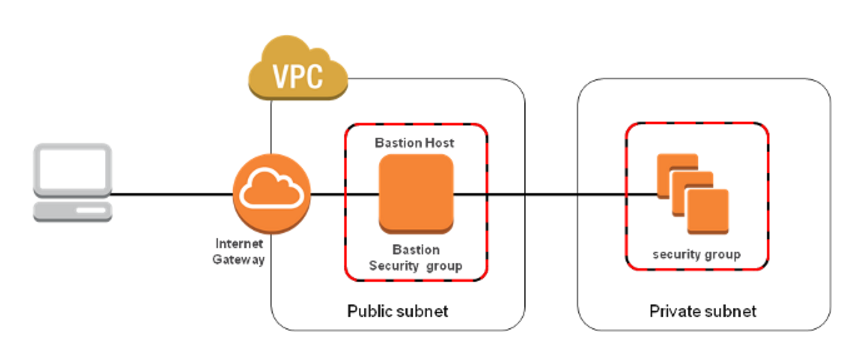
**Bastion Host
Always remember the following when configuring your bastion:
- Never place your SSH private keys on the bastion instance. Instead, use SSH agent forwarding to connect first to the bastion and from there to other instances in private subnets. This lets you keep your SSH private key just on your computer.
- Configure the security group on the bastion to allow SSH connections (TCP/22) only from known and trusted IP addresses.
- Always have more than one bastion. You should have a bastion in each availability zone (AZ) where your instances are. If your deployment takes advantage of a VPC VPN, also have a bastion on premises.
- Configure Linux instances in your VPC to accept SSH connections only from bastion instances.
RDP – port 3389 / TCP
SSH – port 22 /TCP
Below diagram shows connectivity flowing from an end user to resources on a private subnet through an bastion host:

Application Services
*Route 53*
Amazon Route 53 currently supports the following DNS record types:
- A (address record)
- AAAA (IPv6 address record)
- CNAME (canonical name record)
- MX (mail exchange record)
- NS (name server record)
- PTR (pointer record)
- SOA (start of authority record)
- SPF (sender policy framework)
- SRV (service locator)
- TXT (text record)
- Additionally, Amazon Route 53 offers ‘Alias’ records (an Amazon Route 53-specific virtual record).
Alias record work like a CNAME record in that you can map one DNS name ( example.com) to another ‘ target’ DNS name ( test.amazonaws.com) . They differ from a CNAME record in that they are not visible to resolvers. Resolvers only see the A record and the resulting IP address of the target address .
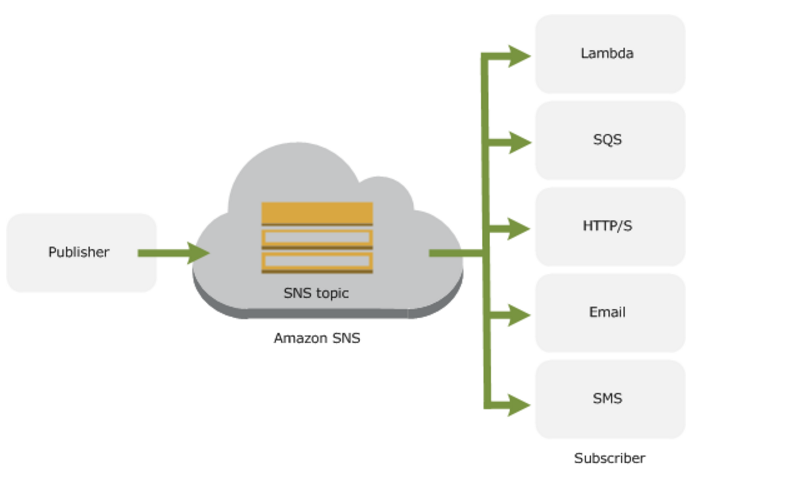
SNS -benefits
- Instantaneous , push-based delivery ( no polling )
- Simple APIs and easy integration with application s
- Flexible message delivery over multiple transport protocols

RAID
RAID 0
When I/O performance is more important than fault tolerance; for example, as in a heavily used database (where data replication is already set up separately).
I/O is distributed across the volumes in a stripe. If you add a volume, you get the straight addition of throughput.
Performance of the stripe is limited to the worst performing volume in the set. Loss of a single volume results in a complete data loss for the array.
RAID 1
When fault tolerance is more important than I/O performance; for example, as in a critical application.
Does not provide a write performance improvement; requires more Amazon EC2 to Amazon EBS bandwidth than non-RAID configurations because the data is written to multiple volumes simultaneousl
**CloudTrial
AWS CloudTrial captures AWS API calls and related events made by or on behalf or an AWS account and delivers log files to an Amazon S3 bucket that you specific . Optionally , you can configure CloudTrial to delivery events to a log group to be monitored by CloudWatch . You can also choose to receive Amazon SNS notifications each time a log file is delivered tou your bucket
**Kinessis
Amazon Kinesis Streams enables you to build custom applications that process or analyze streaming data for specialized needs. You can continuously add various types of data such as clickstreams, application logs, and social media to an Amazon Kinesis stream from hundreds of thousands of sources. Within seconds, the data will be available for your Amazon Kinesis Applications to read and process from the stream.
- By default, Records of a stream are accessible for up to 24 hours from the time they are added to the stream. You can raise this limit to up to 7 days by enabling extended data retention.
- The maximum size of a data blob (the data payload before Base64-encoding) within one record is 1 megabyte (MB).
- Each shard can support up to 1000 PUT records per second.
*** Data Retention – Kinessis
Amazon Kinesis stores your data for up to 24 hours by default. You can raise
data retention period to up to 7 days by enabling extended data retention.
***Monitoring – Kinesis
Amazon Kinesis Stream Management console
Amazon CloudWatch
**Opsworks
– is a configuration magement platform
AWS OpsWorks is a flexible configuration management solution with automation tools that enable you to model and control your applications and their supporting infrastructure
AWS OpsWorks provides three concepts to model your application :
-A Stack is the highest-level management unit
-Layer
-AppF
AWS OpsWorks uses chef recipes to deploy and configure software components on Amazon EC2 instances
**CloudFormation
**AWS Elastic Beanstalk
AWS Elastic Beanstalk is an application management platform
**Workspaces
Amazon WorkSpaces is a managed desktop computing service in the cloud. Amazon WorkSpaces allows customers to easily provision cloud-based desktops that allow end-users to access the documents, applications and resources they need on supported devices including Windows and Mac computers, Chromebooks, iPads, Kindle Fire tablets, and Android tablets. With a few clicks in the AWS Management Console, customers can provision a high-quality cloud desktop experience for any number of users at a cost that is competitive with traditional desktops and half the cost of most Virtual Desktop Infrastructure (VDI) solutions.
*** AWS KMS
*** AWS Trusted Advisor
The AWS Trusted advisor provides for checks at no additional charge to all users
Security Groups – Specific Ports Unrestricted
IAM Use
MFA on root account
Service Limits
AWS Trusted Advisor in the categories of:
- cost optimization,
- performance improvement,
- security
- fault tolerance,
Amazon Machine Images (AWS AMI) offers two types of virtualization: Paravirtual (PV) and Hardware Virtual Machine (HVM).
Each solution offers its own advantages
Every AWS AMI uses the Xen hypervisor on bare metal. Xen offers two kinds of virtualization: HVM (Hardware Virtual Machine) and PV (Paravirtualization). But before we discuss these virtualization capabilities, it’s important to understand how Xen architecture works.
Virtual machines (also known as Guests) run on top of a hypervisor. The hypervisor takes care of CPU scheduling and memory partitioning, but it is unaware of networking, external storage devices, video, or any other common I/O functions found on a computing system.
These guest VMs can be either HVM or PV.
AWS Encryption Models
Server-side encryption
- S3, EBS, RDS, Redshift, WorkMail, Elastic Transcoder
- uses keys in your aws account
Client-side encryption
- S3, EMR, DynamoDB
- encryption happens in application before data submitted the service
- You Supply keys OR use keys in your AWS account